
![]() -Calcul.
n.m.
Calcul dont les termes sont les
-Calcul.
n.m.
Calcul dont les termes sont les ![]() -termes* et les lois sont
celles de la
-termes* et les lois sont
celles de la ![]() -équivalence*.
Le
-équivalence*.
Le ![]() -calcul a été conçu par Church pour remplacer
la théorie des ensembles dans son rôle
de théorie fondamentale des mathématiques pour éviter les
paradoxes d'auto-appartenance.
Malheureusement,
les męmes paradoxes peuvent ętre construits dans le
-calcul a été conçu par Church pour remplacer
la théorie des ensembles dans son rôle
de théorie fondamentale des mathématiques pour éviter les
paradoxes d'auto-appartenance.
Malheureusement,
les męmes paradoxes peuvent ętre construits dans le ![]() -calcul.
-calcul.
Peu aprčs sa conception,
le ![]() -calcul se révélera avoir
la męme puissance de calcul que d'autres formalismes candidats ŕ
représenter les fonctions calculables
(machine de Turing, etc.) [Rosser 84].
Pour cette raison,
et parce que ses termes peuvent ętre interprétés comme des fonctions,
il est le formalisme naturel pour modéliser les langages
de programmation fonctionnelle.
-calcul se révélera avoir
la męme puissance de calcul que d'autres formalismes candidats ŕ
représenter les fonctions calculables
(machine de Turing, etc.) [Rosser 84].
Pour cette raison,
et parce que ses termes peuvent ętre interprétés comme des fonctions,
il est le formalisme naturel pour modéliser les langages
de programmation fonctionnelle.
Le ![]() -calcul a la propriété de Church-Rosser*,
mais pas celle de la normalisation forte*.
-calcul a la propriété de Church-Rosser*,
mais pas celle de la normalisation forte*.
Church a proposé une variante typée du
![]() -calcul [Church 40]
pour éviter les paradoxes.
Ŕ nouveau,
ce formalisme n'a pu servir de théorie fondamentale des mathématiques,
mais cette fois-ci parce que trop faible.
En revanche,
il est le plus simple d'une longue liste de formalismes qui peuvent modéliser
les types en programmation
(
-calcul [Church 40]
pour éviter les paradoxes.
Ŕ nouveau,
ce formalisme n'a pu servir de théorie fondamentale des mathématiques,
mais cette fois-ci parce que trop faible.
En revanche,
il est le plus simple d'une longue liste de formalismes qui peuvent modéliser
les types en programmation
(![]() cube de Barendregt*).
cube de Barendregt*).
![]() -Calcul simplement typé.
n.m.
Calcul dont les termes sont les
-Calcul simplement typé.
n.m.
Calcul dont les termes sont les
![]() -termes simplement typés*
et les lois sont celles de la
-termes simplement typés*
et les lois sont celles de la ![]() -équivalence*.
Le
-équivalence*.
Le ![]() -calcul est le plus simple des calculs
du cube de Barendregt*.
Il a la propriété de Church-Rosser*
et celle de la normalisation forte*.
-calcul est le plus simple des calculs
du cube de Barendregt*.
Il a la propriété de Church-Rosser*
et celle de la normalisation forte*.
Calcul des séquents.
n.m.
(rel. Gentzen*)
[Gallier 86, Gallier 91, Lalement 90]
Présentation symétrique de rčgles de déduction*
qui permet de raisonner sur les preuves.
Le calcul des séquents est défini par un ensemble de
rčgles de déduction qu'il faut juxtaposer pour construire des preuves.
Les séquents qu'on peut trouver ŕ la racine d'une preuve sont des théorčmes.
Les rčgles de déduction pour le calcul des prédicats de premier ordre
(souvent appelé LK)
sont présentées dans la figure 4.

Figure 4: Rčgles du calcul des séquents LK.
Ici, la virgule qui figure dans les antécédents* et les conséquents* est interprétée comme un constructeur de séquence. Si on l'interprčte comme un constructeur de multi-ensembles, on peut oublier les rčgles d'échange. Si on l'interprčte comme un constructeur d'ensembles, on peut aussi oublier les rčgles de contraction. On peut enfin oublier les rčgles d'affaiblissement en remplaçant la rčgle axiome par la suivante.
![]()
Dans la suite, et dans les autres articles, on interprčte la virgule de façon ensembliste.
Le calcul des séquents est qualifié de symétrique car il traite de la męme façon les connecteurs qui apparaissent ŕ gauche et ceux qui apparaissent ŕ droite.
Le principal résultat du calcul des séquents est le Hauptsatz* : la rčgle de coupure est redondante et peut ętre éliminée (avec des précautions si des axiomes sont rajoutés au calcul des séquents).
On peut restreindre syntaxiquement les rčgles du calcul des prédicats
de façon ŕ modéliser exactement le calcul des prédicats intuitionniste.
Pour cela,
il suffit de restreindre les rčgles d'affaiblissement et de la négation
(![]() ) ŕ droite en exigeant que
) ŕ droite en exigeant que
![]() soit vide [Kleene 71].
Une autre restriction,
plus simple et plus radicale,
exige que tous les conséquents soient au plus des singletons.
C'est le systčme qui est souvent appelé LJ.
Cette derničre restriction n'est pas nécessaire logiquement,
malgré ce qui est souvent laissé entendre.
En revanche,
elle est commode pour définir des fragments du calcul des séquents
interprétables en programmation logique
(voir figure 5).
Ces restrictions sont équivalentes
et il suffirait d'admettre un
soit vide [Kleene 71].
Une autre restriction,
plus simple et plus radicale,
exige que tous les conséquents soient au plus des singletons.
C'est le systčme qui est souvent appelé LJ.
Cette derničre restriction n'est pas nécessaire logiquement,
malgré ce qui est souvent laissé entendre.
En revanche,
elle est commode pour définir des fragments du calcul des séquents
interprétables en programmation logique
(voir figure 5).
Ces restrictions sont équivalentes
et il suffirait d'admettre un ![]() non-vide dans l'une des deux rčgles
pour retrouver le calcul des prédicats classique.
non-vide dans l'une des deux rčgles
pour retrouver le calcul des prédicats classique.

Figure 5: Rčgles du calcul des séquents intuitionnistes.
C'est ce calcul qui sert de base logique ŕ
![]() Prolog.
Il pourrait aussi servir pour Prolog,
mais ce n'est pas l'habitude.
Dans ce cadre,
l'antécédent des séquents modélise le programme
et le conséquent modélise le but*.
La notion de preuve uniforme*
fournit une sémantique opérationnelle pour ces langages.
On peut définir d'autres calculs des séquents pour d'autres logiques
(par exemple, la logique linéaire [Girard et al. 89]),
et pour ces calculs définir une notion de preuve uniforme et rechercher les
fragments de ces calculs pour lesquels la prouvabilité uniforme est complčte.
Miller considčre que ces fragments sont tous des langages de programmation
logique [Miller 91c, Miller et al. 91].
Prolog.
Il pourrait aussi servir pour Prolog,
mais ce n'est pas l'habitude.
Dans ce cadre,
l'antécédent des séquents modélise le programme
et le conséquent modélise le but*.
La notion de preuve uniforme*
fournit une sémantique opérationnelle pour ces langages.
On peut définir d'autres calculs des séquents pour d'autres logiques
(par exemple, la logique linéaire [Girard et al. 89]),
et pour ces calculs définir une notion de preuve uniforme et rechercher les
fragments de ces calculs pour lesquels la prouvabilité uniforme est complčte.
Miller considčre que ces fragments sont tous des langages de programmation
logique [Miller 91c, Miller et al. 91].
Church,
Alonzo (États-Unis, 1903-1995).
Church introduit le ![]() -calcul dans les années 1930
comme une notation pour la logique combinatoire
(
-calcul dans les années 1930
comme une notation pour la logique combinatoire
(![]() Curry*)
et le développe avec Rosser* et Kleene.
Il démontre en 1936 l'indécidabilité du calcul des
prédicats [Church 36].
Au passage,
il énonce ce qui sera connu comme la «thčse de Church»,
selon laquelle la théorie des fonctions récursives générales
modélise adéquatement la notion de fonction calculable.
Curry*)
et le développe avec Rosser* et Kleene.
Il démontre en 1936 l'indécidabilité du calcul des
prédicats [Church 36].
Au passage,
il énonce ce qui sera connu comme la «thčse de Church»,
selon laquelle la théorie des fonctions récursives générales
modélise adéquatement la notion de fonction calculable.
Il présente en 1940 une logique d'ordre
supérieur [Church 40] dont beaucoup
de traits sont représentés en ![]() Prolog.
Prolog.
Church (entier de).
n.m.
Représentation des entiers naturels par des
![]() -termes* :
-termes* :
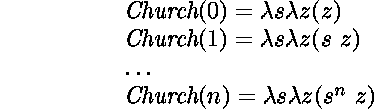
Des représentations similaires peuvent ętre produites automatiquement pour tous les types inductifs* [Böhm et Berarducci 85, Pierce et al. 89].
On peut spécifier en ![]() Prolog la représentation de Church des entiers naturels.
Prolog la représentation de Church des entiers naturels.
type entier_church ((A->A)->A->A) -> o .
entier_church s
entier_church s![]() z
z![]() z .
z .
![]() z
z![]() ( N s (s z) ) :- entier_church N .
( N s (s z) ) :- entier_church N .
On peut remplacer la derničre clause par la suivante,
entier_church s![]() z
z![]() ( s (N s z) ) :- entier_church N .
( s (N s z) ) :- entier_church N .
qui a l'avantage d'appartenir au fragment
![]() * de
* de ![]() Prolog.
Prolog.
On peut aussi axiomatiser cette représentation ŕ l'aide la quantification universelle :
entier_church N :- pi z![]() ( (N x
( (N x![]() x z) = z ).
x z) = z ).
On peut remplacer cette clause par la suivante,
entier_church N :- z![]() (N x
(N x![]() x z) = z
x z) = z![]() z .
z .
grâce ŕ la correspondance entre quantifications
essentiellement universelles*,
et plus précisément,
grâce ŕ l'axiome de
![]() -équivalence*.
-équivalence*.
Church (Type ŕ la).
n.m.
Point de vue sur le typage oů la
vérification du bon typage d'une construction est un préalable ŕ
l'énonciation de sa sémantique.
Ce point de vue s'oppose ŕ celui dit de
Curry*.
Il correspond au typage prescriptif* des programmes Prolog.
Church-Rosser.
Propriété d'un systčme de réécriture selon laquelle quand un
terme est le point de départ de plusieurs dérivations, elles
convergent :
![]() A
A![]() B
B![]() C[ (A
C[ (A ![]() B
B ![]() A
A ![]() C)
C)
![]()
![]() D[B
D[B ![]() D
D ![]() C
C ![]() D] ].
D] ].
Le ![]() -calcul* a cette propriété,
ainsi que tous les calculs du cube de Barendregt*.
-calcul* a cette propriété,
ainsi que tous les calculs du cube de Barendregt*.
1)
Dans la forme normale conjonctive* (![]() ),
une clause est une disjonction de littéraux*.
Une formule
),
une clause est une disjonction de littéraux*.
Une formule ![]() est une conjonction de clauses.
est une conjonction de clauses.
2)
Unité de sens d'un programme Prolog
ou ![]() Prolog.
(
Prolog.
(![]() clause définie*)
clause définie*)
Clause définie.
n.f.
(en anglais, definite clause)
1)
(![]() clause de Horn*)
clause de Horn*)
2) Une formule qui a la forme d'une implication dont la tęte est atomique et la prémisse quelconque. En ce sens les formules héréditaires de Harrop* sont des clauses définies.
Clause dynamique.
n.f.
(rel. clause*)
Clause ajoutée ŕ un programme par l'effet de l'implication dans les buts
de ![]() Prolog.
Prolog.
Colmerauer,
Alain (France).
Ŕ la suite de travaux sur le traitement automatique de la langue naturelle,
Alain Colmerauer propose d'utiliser comme un langage de programmation
le formalisme développé ŕ cette occasion [Colmerauer 70].
Ce formalisme deviendra Prolog*
[Battani et Meloni 73, Roussel 75, Colmerauer et al. 79].
Alors que le domaine de calcul de Prolog est celui des termes de premier
ordre munis d'une égalité syntaxique,
Colmerauer propose d'étendre ce domaine ŕ plus de termes munis de plus de
relations.
Le systčme Prolog ![]() étend le domaine aux termes rationnels*
munis de l'égalité appropriée et d'une relation de diségalité
(dif) [Colmerauer 82, Colmerauer et al. 82, Giannesini et Cohen 84, Van Caneghem 86, Coupet-Grimal 88, Coupet-Grimal 91].
De plus,
Prolog
étend le domaine aux termes rationnels*
munis de l'égalité appropriée et d'une relation de diségalité
(dif) [Colmerauer 82, Colmerauer et al. 82, Giannesini et Cohen 84, Van Caneghem 86, Coupet-Grimal 88, Coupet-Grimal 91].
De plus,
Prolog ![]() assouplit la stratégie de calcul en donnant le moyen de la
faire dépendre du flot de donnée (freeze).
Ce systčme est un premier pas vers la programmation logique avec contraintes.
Celle-ci sera réalisée,
ŕ Marseille,
par les systčmes
Prolog
assouplit la stratégie de calcul en donnant le moyen de la
faire dépendre du flot de donnée (freeze).
Ce systčme est un premier pas vers la programmation logique avec contraintes.
Celle-ci sera réalisée,
ŕ Marseille,
par les systčmes
Prolog ![]() [Colmerauer 90]
(contraintes sur les rationnels, les booléens et les chaînes)
et Prolog
[Colmerauer 90]
(contraintes sur les rationnels, les booléens et les chaînes)
et Prolog ![]() [Benhamou et Touraïvane 95]
(męmes domaines de contraintes plus intervalles et de nouveaux algorithmes),
et par de nombreux autres systčmes dans le
monde [Jaffar et Lassez 86, Van Hentenryck 89, Cohen 90].
[Benhamou et Touraïvane 95]
(męmes domaines de contraintes plus intervalles et de nouveaux algorithmes),
et par de nombreux autres systčmes dans le
monde [Jaffar et Lassez 86, Van Hentenryck 89, Cohen 90].
Alain Colmerauer est actuellement (1998) professeur ŕ l'université d'Aix-Marseille.
1)
Désigne un ![]() -terme qui n'a pas de variables
libres*.
La situation se complique en
-terme qui n'a pas de variables
libres*.
La situation se complique en ![]() Prolog car il y deux sortes de variables :
les variables logiques* et les
Prolog car il y deux sortes de variables :
les variables logiques* et les ![]() -variables*.
En
-variables*.
En ![]() Prolog, on appelle combinateur un
Prolog, on appelle combinateur un ![]() -terme
qui n'a pas de
-terme
qui n'a pas de
![]() -variables libres
męme s'il contient des variables logiques libres.
Cette notion a un rôle important dans
la pragmatique de
-variables libres
męme s'il contient des variables logiques libres.
Cette notion a un rôle important dans
la pragmatique de ![]() Prolog [Belleannée et al. 95] et dans son
implémentation [Brisset et Ridoux 91].
Prolog [Belleannée et al. 95] et dans son
implémentation [Brisset et Ridoux 91].
D'un point de vue pragmatique,
il est important de voir que le domaine de
calcul de ![]() Prolog est uniquement composé de combinateurs ;
tous les paramčtres de prédicat,
et toutes les variables logiques désignent des combinateurs.
En particulier,
il n'y a aucun moyen direct de manipuler le corps d'une abstraction si celui-ci
n'est pas dégénéré et comporte bien des occurrences libres de
la variable abstraite.
De plus,
la propriété d'ętre un combinateur est conservée
par les substitutions solutions du problčme d'unification des
Prolog est uniquement composé de combinateurs ;
tous les paramčtres de prédicat,
et toutes les variables logiques désignent des combinateurs.
En particulier,
il n'y a aucun moyen direct de manipuler le corps d'une abstraction si celui-ci
n'est pas dégénéré et comporte bien des occurrences libres de
la variable abstraite.
De plus,
la propriété d'ętre un combinateur est conservée
par les substitutions solutions du problčme d'unification des
![]() -termes simplement typés.
Les combinateurs détectés ŕ la compilation seront donc toujours
des combinateurs lors de l'exécution.
Noter que les sous-termes d'un combinateur
peuvent ne pas ętre des combinateurs
s'ils ne sont pas passés en paramčtre d'un prédicat,
et s'ils ne sont pas substitués ŕ une variable logique.
-termes simplement typés.
Les combinateurs détectés ŕ la compilation seront donc toujours
des combinateurs lors de l'exécution.
Noter que les sous-termes d'un combinateur
peuvent ne pas ętre des combinateurs
s'ils ne sont pas passés en paramčtre d'un prédicat,
et s'ils ne sont pas substitués ŕ une variable logique.
La détection des combinateurs est importante
car elle donne un critčre pour améliorer
la procédure de ![]() -réduction*.
En effet,
alors que la réduction de graphes* naďve duplique le terme
de gauche d'un
-réduction*.
En effet,
alors que la réduction de graphes* naďve duplique le terme
de gauche d'un
![]() -rédex*,
ses sous-termes qui sont des combinateurs
peuvent ętre partagés sans autre précaution.
Nos expériences ont montré que cette heuristique apporte un gain de complexité
et augmente la réutilisation des structures de données,
et donc le partage de représentation*
(voir la section «Le rôle des combinateurs»*).
-rédex*,
ses sous-termes qui sont des combinateurs
peuvent ętre partagés sans autre précaution.
Nos expériences ont montré que cette heuristique apporte un gain de complexité
et augmente la réutilisation des structures de données,
et donc le partage de représentation*
(voir la section «Le rôle des combinateurs»*).
2) Désigne un terme de la logique combinatoire*. Les deux acceptions sont cependant trčs proches.
Compilation de l´implication.
n.f.
(![]() implication*)
La lecture opérationnelle de la rčgle de déduction de l'implication ŕ droite
(
implication*)
La lecture opérationnelle de la rčgle de déduction de l'implication ŕ droite
(![]() calcul des séquents*) est que prouver un but
calcul des séquents*) est que prouver un but
![]() dans un programme
dans un programme ![]() nécessite de
prouver le but
nécessite de
prouver le but ![]() dans le programme
dans le programme ![]() augmenté de la clause
augmenté de la clause ![]() .
Cette lecture laisse penser que le programme est une entité dynamique qui peut
difficilement ętre compilée.
.
Cette lecture laisse penser que le programme est une entité dynamique qui peut
difficilement ętre compilée.
En fait, on peut compiler séparément les clauses dynamiques* et les ajouter ŕ la demande au programme par une sorte d'édition de lien dynamique. Comme les clauses dynamiques peuvent contenir des variables libres, ce qui est réellement compilé est une clôture des clauses. Cela peut ętre formalisé de la maničre suivante.
Une clause dynamique ![]() d'un prédicat
d'un prédicat
![]() avec les variables libres
avec les variables libres ![]() est compilée en
est compilée en
![]() ,
oů
,
oů ![]() est une constante nouvelle.
L'ajout de la clause dynamique dans un contexte oů les variables libres valent
est une constante nouvelle.
L'ajout de la clause dynamique dans un contexte oů les variables libres valent
![]() introduit la paire
introduit la paire
![]() dans la continuation de programme*.
L'exécution d'un but
dans la continuation de programme*.
L'exécution d'un but ![]() recherche les paires <p,c> et
appelle
recherche les paires <p,c> et
appelle ![]() ,
soit
,
soit ![]() qui fait le lien ŕ la fois avec les paramčtre effectifs (
qui fait le lien ŕ la fois avec les paramčtre effectifs (![]() )
et avec le contexte oů sont définies les variables libres de la clause
(
)
et avec le contexte oů sont définies les variables libres de la clause
(![]() ).
).
Conclusion.
n.f.
(![]() rčgle de déduction*)
rčgle de déduction*)
Condition de tęte.
n.f.
(parfois appelée «généricité définitionnelle» pour
definitional genericity)
La condition de tęte prescrit que toutes les occurrences d'un męme
symbole prédicatif en tęte de clause ont des types qui sont des
renommages du schéma de type du symbole prédicatif.
Cette condition s'ajoute donc ŕ la condition de typage
«ŕ la ![]() » qui prescrit
que les occurrences d'un symbole ont des types qui sont des instances
indépendantes du schéma de type du symbole.
Cette condition élimine un style de programmation courant en Prolog
non typé dans lequel contenant et contenu
(par exemple, listes et éléments) sont traités par le męme prédicat,
et elle rend l´inférence de type*
équivalente au problčme de semi-unification non-uniforme
et donc indécidable [Kfoury et al. 93].
Néanmoins,
cette condition est nécessaire pour
que le typage cohabite harmonieusement avec des manipulations de programmes
importantes et avec la modularité des programmes
(
» qui prescrit
que les occurrences d'un symbole ont des types qui sont des instances
indépendantes du schéma de type du symbole.
Cette condition élimine un style de programmation courant en Prolog
non typé dans lequel contenant et contenu
(par exemple, listes et éléments) sont traités par le męme prédicat,
et elle rend l´inférence de type*
équivalente au problčme de semi-unification non-uniforme
et donc indécidable [Kfoury et al. 93].
Néanmoins,
cette condition est nécessaire pour
que le typage cohabite harmonieusement avec des manipulations de programmes
importantes et avec la modularité des programmes
(![]() typage paramétrique*).
typage paramétrique*).
La condition de tęte est admise implicitement
dans le systčme de types pour Prolog
de Mycroft et O'Keefe
[Mycroft et O'Keefe 84].
Elle figure sous le nom de «condition de tęte» (head condition)
dans les propositions de Hanus,
et de Hill et Lloyd [Hanus 91, Hill et Lloyd 94],
et sous le nom de «généricité définitionnelle»
(definitional genericity)
dans la proposition de Lakshman et Reddy [Lakshman et Reddy 91].
Cette condition n'est pas décrite dans la définition de
![]() Prolog
et elle est écartée dans la proposition
de Nadathur et Pfenning [Nadathur et Pfenning 92].
Elle est adopté dans l'implémentation
Prolog
et elle est écartée dans la proposition
de Nadathur et Pfenning [Nadathur et Pfenning 92].
Elle est adopté dans l'implémentation
![]() * de
* de ![]() Prolog.
Prolog.
Beaucoup de programmes classiques en Prolog non-typé violeraient la condition de tęte si on les typait. Ces programmes correspondent souvent ŕ des pratiques qui ne sont pas déclaratives et qui sont condamnables męme dans le cas non-typé [O'Keefe 90]. Il subsiste des cas oů les programmes interdits sont légitimes, mais une discipline de typage paramétrique* accepte ces programmes.
Condition de transparence.
n.f.
Condition selon laquelle les variables de type* qui apparaissent
dans une déclaration de type doivent apparaître dans le type résultat.
Conjointement avec la condition de tęte*
cette condition permet de
démontrer un théorčme de correction sémantique* pour Prolog.
On dit d'un type déclaré qui ne vérifie pas la condition de transparence qu'il oublie les variables de type qui n'apparaissent pas dans le type résultat. On dit des instances de ces variables que ce sont des types oubliés*.
Par exemple, les types de nil ((list A)) et cons (A->(list A)->(list A)) vérifient la condition de transparence : la seule variable, A, apparaît dans le type résultat. Le type de conc ((list A)->(list A)->(list A)->o) ne la vérifie pas, et plus généralement aucun type de prédicat polymorphe ne la vérifie. En effet, la variable A n'apparaît pas dans le type résultat, o.
Conséquent.
n.m.
(![]() séquent*)
séquent*)
Constante universelle.
n.f.
(rel. élimination des quantificateur*)
(en anglais, eigen-value)
Constante utilisée pour éliminer une
quantification essentiellement universelle*.
Elle doit ętre nouvelle, c'est-ŕ-dire ne pas avoir d'occurrence
libre*
dans la formule quantifiée ou dans son contexte
(voir aussi les rčgles du calcul des séquents* :
introduction ŕ droite de la quantification universelle
et ŕ gauche de la quantification existentielle).
Constructeur de termes.
n.m.
(rel. type simple*)
Symbole fonctionnel qui peut ętre appliqué ŕ des arguments dont la nature
dépend du domaine de termes en vigueur pour former un terme.
Par exemple,
dans un domaine de premier ordre*,
les arguments doivent ętre des termes en męme nombre que
l´arité* du constructeur.
Dans un domaine de termes typés,
les arguments doivent en plus avoir des types compatibles
avec le type du constructeur de terme.
En ![]() Prolog*,
les constructeurs de termes sont introduits par la déclaration type.
Par exemple la déclaration suivante
Prolog*,
les constructeurs de termes sont introduits par la déclaration type.
Par exemple la déclaration suivante
type abs (l_terme->l_terme) -> l_terme .
introduit le constructeur de terme abs et spécifie qu'il peut ętre appliqué ŕ un terme de type l_terme->l_terme pour former un terme de type l_terme.
Constructeur de types.
n.m.
(rel. type simple*)
Dans un langage typé,
symbole fonctionnel qui peut ętre appliqué ŕ des arguments dont la nature
dépend du langage pour former un type.
En ![]() Prolog*,
les constructeurs de types sont introduits par la déclaration kind.
Par exemple,
la déclaration suivante
Prolog*,
les constructeurs de types sont introduits par la déclaration kind.
Par exemple,
la déclaration suivante
kind list type -> type .
introduit le constructeur de type list et spécifie qu'il doit ętre appliqué ŕ un type pour former un type.
Continuation.
n.f.
Structure de données abstraite qui permet de formaliser le contrôle
des langages de programmation en notant les calculs qu'il reste
ŕ faire.
Les continuations ont été introduites pour décrire le contrôle
des langages de programmation impératifs,
puis fonctionnels,
puis logiques.
Dans les deux premiers cas, une continuation suffit, mais dans le cas de la programmation logique, deux sont nécessaires [Nicholson et Foo 89, Consel et Khoo 91]. L'une correspond ŕ la résolvante* et est appelée la continuation de succčs (que faire en cas de succčs ?), l'autre correspond ŕ la pile de recherche* et est appelée la continuation d'échec (que faire en cas d'échec ?).
Les équations suivantes présentent un systčme d'équations qui
définit la sémantique de Prolog en termes de continuations.
La continuation de succčs
(notée ![]() )
détermine le calcul ŕ faire ŕ la suite du succčs d'un but.
On la voit passée en paramčtre dans la traduction d'un but élémentaire,
)
détermine le calcul ŕ faire ŕ la suite du succčs d'un but.
On la voit passée en paramčtre dans la traduction d'un but élémentaire,
![]() ,
et on voit sa construction dans la traduction d'un but complexe,
,
et on voit sa construction dans la traduction d'un but complexe,
![]() .
La condition d'échec
(notée
.
La condition d'échec
(notée ![]() )
détermine le calcul ŕ faire ŕ la suite de l'échec d'un but.
On la voit passée en paramčtre dans la traduction d'un but élémentaire,
et on voit sa construction dans la traduction d'une conjonction de clauses
d'un męme prédicat,
)
détermine le calcul ŕ faire ŕ la suite de l'échec d'un but.
On la voit passée en paramčtre dans la traduction d'un but élémentaire,
et on voit sa construction dans la traduction d'une conjonction de clauses
d'un męme prédicat,
![]() .
L'unification est représentée par la constante
.
L'unification est représentée par la constante
![]() ,
et on peut voir dans sa spécification comment les deux continuations
sont exploitées lors du succčs ou de l'échec de l'unification.
Partout,
la variable
,
et on peut voir dans sa spécification comment les deux continuations
sont exploitées lors du succčs ou de l'échec de l'unification.
Partout,
la variable ![]() représente les paramčtres effectifs d'un appel
ŕ un prédicat.
représente les paramčtres effectifs d'un appel
ŕ un prédicat.
![]()
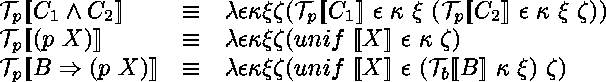
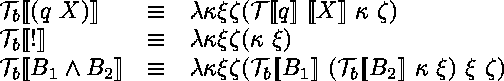
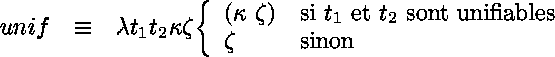
Comme cela a été fait pour les langages de programmation fonctionnels,
on peut capturer (réifier*) les continuations de la
programmation logique afin de modéliser la coupure*
et la gestion d'exceptions
[Brisset 92, Brisset et Ridoux 93].
Tous les systčmes Prolog proposent la coupure,
et beaucoup la gestion d'exceptions,
mais il est difficile de modéliser ces deux mécanismes dans le cadre de
la sémantique opérationnelle basée sur la résolution*.
Cela devient assez simple dans le modčle des continuations.
La continuation d'échec ŕ l'entrée dans un prédicat est capturée dans une
variable ![]() dans la traduction d'une clause,
dans la traduction d'une clause,
![]() ,
et elle est réfléchie*
dans la continuation d'échec dans la traduction de
la coupure,
,
et elle est réfléchie*
dans la continuation d'échec dans la traduction de
la coupure,
![]() .
Dans celle-ci,
la continuation d'échec en entrée,
.
Dans celle-ci,
la continuation d'échec en entrée,
![]() ,
est ignorée et remplacée par la continuation d'échec capturée,
,
est ignorée et remplacée par la continuation d'échec capturée,
![]() .
.
Il faut noter que cette sémantique spécifie l'ordre de sélection des
clauses et des buts,
ce que la sémantique de Prolog basée sur la résolution ne fait pas.
La sémantique basée sur les continuations est donc plus fidčle ŕ la
majorité des systčmes Prolog,
mais elle permet difficilement de rendre compte de stratégies plus dynamiques
sauf ŕ écrire l'équivalent d'un ordonnenceur de buts et de clauses en
![]() -calcul.
Ce surcroît de précision est toutefois nécessaire pour donner la sémantique de
la coupure.
-calcul.
Ce surcroît de précision est toutefois nécessaire pour donner la sémantique de
la coupure.
On peut imaginer une variante de la coupure inspirée de la capture de continuation en Scheme. Un prédicat call_fc permet d'appeler un but en lui passant la continuation d'échec en paramčtre (réification), et un prédicat cut prend en paramčtre une continuation d'échec capturée et l'installe comme continuation d'échec courante (réflexion).
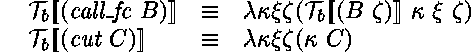
Quand on passe ŕ ![]() Prolog,
la situation se complique car il faut tenir compte de la sémantique des
clauses ajoutées par implication,
et des quantifications universelles.
Pour cela on ajoute deux nouvelles continuations.
L'une,
Prolog,
la situation se complique car il faut tenir compte de la sémantique des
clauses ajoutées par implication,
et des quantifications universelles.
Pour cela on ajoute deux nouvelles continuations.
L'une, ![]() , est destinée ŕ gérer l'évolution du programme,
l'autre,
, est destinée ŕ gérer l'évolution du programme,
l'autre, ![]() , celle de la signature.
Les équations suivantes donnent la sémantique de
, celle de la signature.
Les équations suivantes donnent la sémantique de ![]() Prolog
en termes de continuations.
La continuation de signature est essentiellement un entier qui permet de
produire des
Prolog
en termes de continuations.
La continuation de signature est essentiellement un entier qui permet de
produire des ![]() toujours nouveaux dans une męme branche de
preuve
(voir l'équation pour
toujours nouveaux dans une męme branche de
preuve
(voir l'équation pour ![]() ).
La continuation de programme est un tableau de dénotations de paquets de
clauses dynamiques* indexé par les prédicats.
On écrira donc
).
La continuation de programme est un tableau de dénotations de paquets de
clauses dynamiques* indexé par les prédicats.
On écrira donc ![]() pour désigner
les clauses dynamiques du prédicat
pour désigner
les clauses dynamiques du prédicat ![]() .
Ŕ chaque fois qu'une clause est ajouté ŕ un prédicat,
sa dénotation est composée avec celle du paquet de clauses dynamiques de ce
prédicat
(voir l'équation pour
.
Ŕ chaque fois qu'une clause est ajouté ŕ un prédicat,
sa dénotation est composée avec celle du paquet de clauses dynamiques de ce
prédicat
(voir l'équation pour ![]() ).
).
![]()
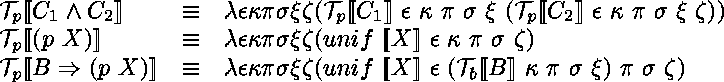
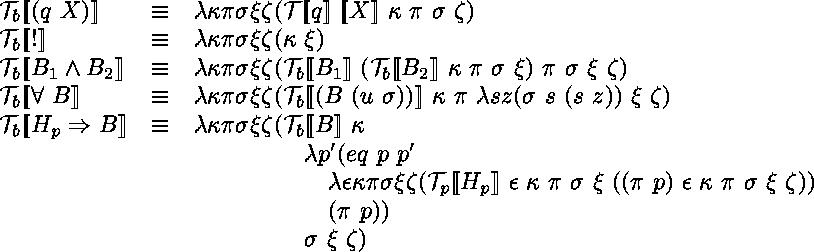
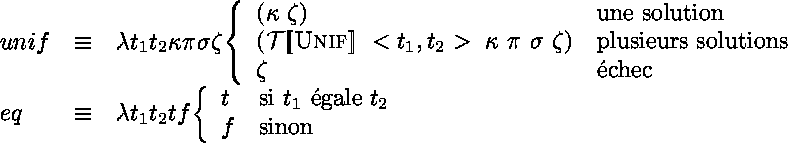
La définition de ![]() fait référence ŕ un prédicat
fait référence ŕ un prédicat ![]() qui est sensé
implémenter l´unification d´ordre supérieur*.
Cela permet de sous-traiter ŕ la sémantique des prédicats la gestion de
l'indéterminisme du problčme d'unification.
C'est ce qui est fait dans le systčme
qui est sensé
implémenter l´unification d´ordre supérieur*.
Cela permet de sous-traiter ŕ la sémantique des prédicats la gestion de
l'indéterminisme du problčme d'unification.
C'est ce qui est fait dans le systčme
![]() *.
*.
Ici encore,
la sémantique basée sur les continuations fixe un ordre de sélection des
clauses dynamiques,
alors que celle qui est basée sur le calcul des séquents n'en fixe aucun.
Cependant,
la sémantique basée sur les continuations précise un comportement possible
de la coupure vis-ŕ-vis des clauses dynamiques
(le comportement effectif du systčme ![]() ).
).
Correction sémantique.
n.f.
Propriété d'une classe de programmes typés
dont l'exécution ne peut pas causer d'erreurs de type
s'ils sont bien typés,
«Well-typed programs cannot go wrong» [Milner 78].
Les programmes de cette classe n'ont pas besoin que les types soient représentés ŕ l'exécution. Inversement, les autres programmes ont besoin que des types soient représentés ŕ l'exécution, mais pas forcément tous.
Dans le cas de Prolog*, le résultat est le suivant : un programme qui vérifie la condition de transparence*, est constitué de clauses bien typées et dont les prédicats vérifient la condition de tęte*, ne peut pas causer d'erreur de type ŕ l'exécution [Hanus 91].
1)
Rčgle du calcul des séquents* qui modélise l'utilisation d'un lemme
dans une démonstration
(![]() Hauptsatz*).
Hauptsatz*).
2) Opérateur de contrôle de la stratégie de recherche de Prolog noté «!» dans la syntaxe standard*. Il permet d'élaguer l'arbre de recherche.
Currifier.
v. tr.
Représenter une fonction ŕ ![]() paramčtres,
paramčtres,
![]() ,
par une fonction qui prend
le premier paramčtre et qui rend une fonction qui prend le deuxičme
paramčtre, etc.,
,
par une fonction qui prend
le premier paramčtre et qui rend une fonction qui prend le deuxičme
paramčtre, etc.,
![]()
![]() (ou plus simplement
(ou plus simplement
![]()
![]() ).
Cette possibilité observée d'abord par Frege, puis Shönfinkel,
est couramment attribuée ŕ Curry*.
Elle trouve une généralisation dans la notion d'isomorphisme de
type [Di Cosmo 95].
).
Cette possibilité observée d'abord par Frege, puis Shönfinkel,
est couramment attribuée ŕ Curry*.
Elle trouve une généralisation dans la notion d'isomorphisme de
type [Di Cosmo 95].
Curry,
Haskell Brooks (États-Unis, 1900-1982).
Haskell Curry est le principal contributeur de la
logique combinatoire [Curry et al. 68].
Cette logique est intimement reliée au
![]() -calcul* [Hindley et Seldin 86],
et son influence va jusqu'ŕ la programmation
fonctionnelle [Revesz 88].
-calcul* [Hindley et Seldin 86],
et son influence va jusqu'ŕ la programmation
fonctionnelle [Revesz 88].
Curry (type ŕ la).
n.m.
Point de vue sur le typage oů le bon typage est
une propriété complčtement indépendante de la sémantique.
Il n'est pas nécessaire qu'un programme soit bien typé pour lui donner une
sémantique.
Ce point de vue s'oppose ŕ celui dit de
Church*.
Il correspond au typage descriptif* des programmes Prolog.
Curry-Howard (correspondance/isomorphisme de).
La correspondance de Curry-Howard formalise le parallčle entre types et termes
d'une part,
et formules et preuves d'autre
part [Curry et al. 68, Howard 80].
Cette correspondance est plus ou moins étroite selon les systčmes logiques,
et elle constitue męme parfois un
isomorphisme [Barendregt et Hemerik 90, Barendregt 91].
Par exemple,
le ![]() -calcul simplement typé* est en
correspondance de Curry-Howard avec le fragment du calcul propositionnel
intuitionniste muni de la seule implication :
la flčche de type correspond ŕ l'implication,
les
-calcul simplement typé* est en
correspondance de Curry-Howard avec le fragment du calcul propositionnel
intuitionniste muni de la seule implication :
la flčche de type correspond ŕ l'implication,
les ![]() -termes simplement typés*
correspondent aux preuves en déduction naturelle.
Des systčmes de type plus riches
(par exemple, ceux du cube de Barendregt*)
correspondent ŕ des logiques munies de plus de connecteurs.
Avec des systčmes de types trop riches,
la correspondance ne peut ętre utilisée que comme une métaphore.
-termes simplement typés*
correspondent aux preuves en déduction naturelle.
Des systčmes de type plus riches
(par exemple, ceux du cube de Barendregt*)
correspondent ŕ des logiques munies de plus de connecteurs.
Avec des systčmes de types trop riches,
la correspondance ne peut ętre utilisée que comme une métaphore.
Dans le cadre de la programmation, la correspondance de Curry-Howard s'étend aux spécifications et aux programmes : un programme (correct) est la preuve qu'une spécification est réalisable (dans le langage de programmation correspondant au langage des preuves), de la męme façon qu'un terme (bien typé) est la preuve qu'un type est habité. Dans ce cadre [Huet et al. 97], on fait jouer aux types le rôle de spécifications et un démonstrateur automatique en extrait un programme. Deux problčmes se font jour : la spécification peut ne pas ętre réalisable dans le langage des preuves du systčme logique, ou bien la spécification est réalisable, mais pas par un algorithme raisonnable.