La ![]() -rķduction* est une opķration fondamentale de
-rķduction* est une opķration fondamentale de ![]() Prolog,
et elle se fait principalement Ó la demande de l'unification pour
normaliser les termes Ó comparer et accessoirement Ó la demande du programmeur
pour rendre les termes plus lisibles ou plus compacts.
Prolog,
et elle se fait principalement Ó la demande de l'unification pour
normaliser les termes Ó comparer et accessoirement Ó la demande du programmeur
pour rendre les termes plus lisibles ou plus compacts.
Le problĶme posķ en ![]() Prolog diffĶre beaucoup de celui posķ pour les langages
de programmation fonctionnelle.
En gķnķral,
ces derniers ½ne rķduisent pas sous les lambdas╗,
alors qu'en
Prolog diffĶre beaucoup de celui posķ pour les langages
de programmation fonctionnelle.
En gķnķral,
ces derniers ½ne rķduisent pas sous les lambdas╗,
alors qu'en
![]() Prolog il faut presque toujours le faire.
Cela vient de ce que les langages de programmation fonctionnelle ne permettent
pas de comparer des fonctions,
alors que cette opķration est au c
Prolog il faut presque toujours le faire.
Cela vient de ce que les langages de programmation fonctionnelle ne permettent
pas de comparer des fonctions,
alors que cette opķration est au c![]() ur de
ur de ![]() Prolog.
En
Prolog.
En ![]() Prolog,
la
Prolog,
la ![]() -rķduction doit Ļtre combinķe avec la
substitution de variable logique*
et le retour-arriĶre.
Dans cette combinaison,
la
-rķduction doit Ļtre combinķe avec la
substitution de variable logique*
et le retour-arriĶre.
Dans cette combinaison,
la ![]() -rķduction peut produire des formes normales dites
flexibles*
que la substitution de variable logique peut rendre non-normales.
De plus,
le retour-arriĶre peut inverser toutes les transitions de normale Ó non-normale
et vice-versa.
Enfin,
en
-rķduction peut produire des formes normales dites
flexibles*
que la substitution de variable logique peut rendre non-normales.
De plus,
le retour-arriĶre peut inverser toutes les transitions de normale Ó non-normale
et vice-versa.
Enfin,
en ![]() Prolog,
aucune opķration Ó effet de bord n'est
attachķe Ó la
Prolog,
aucune opķration Ó effet de bord n'est
attachķe Ó la ![]() -rķduction
et le
-rķduction
et le ![]() -calcul utilisķ,
le
-calcul utilisķ,
le ![]() -calcul simplement typķs*,
est fortement normalisable* ;
l'ordre de
-calcul simplement typķs*,
est fortement normalisable* ;
l'ordre de
![]() -rķduction est donc absolument quelconque,
y compris d'une fois sur l'autre.
-rķduction est donc absolument quelconque,
y compris d'une fois sur l'autre.
Nous avons choisi de reprķsenter les ![]() -termes par des graphes,
et d'implķmenter la
-termes par des graphes,
et d'implķmenter la
![]() -rķduction par rķduction de graphe*.
C'est une autre diffķrence avec le projet de
Gopalan Nadathur [Nadathur et Wilson 90] o∙ il est prķvu
d'employer la reprķsentation de
de Bruijn*
et des environnements reprķsentant les substitutions de
-rķduction par rķduction de graphe*.
C'est une autre diffķrence avec le projet de
Gopalan Nadathur [Nadathur et Wilson 90] o∙ il est prķvu
d'employer la reprķsentation de
de Bruijn*
et des environnements reprķsentant les substitutions de ![]() -variable.
En fait,
il ne faut pas trop insister sur ces diffķrences,
car pas plus Gopalan Nadathur et ses collĶgues que nous,
n'avons pensķ utiliser un schķma pur.
Par exemple,
nous combinons la rķduction de graphe avec des notations de
substitution explicite*
et Nadathur envisage la substitution in-situ de
-variable.
En fait,
il ne faut pas trop insister sur ces diffķrences,
car pas plus Gopalan Nadathur et ses collĶgues que nous,
n'avons pensķ utiliser un schķma pur.
Par exemple,
nous combinons la rķduction de graphe avec des notations de
substitution explicite*
et Nadathur envisage la substitution in-situ de
![]() -rķdex*.
-rķdex*.
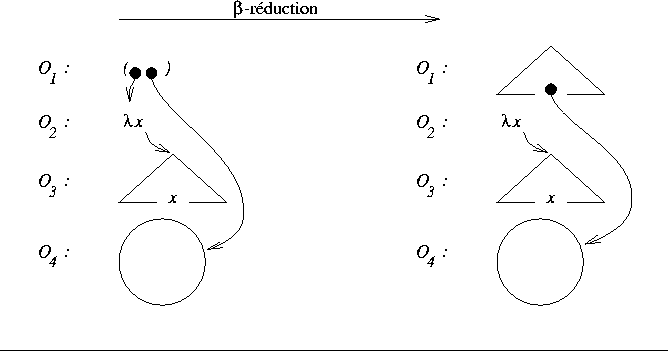
Figure 2: Rķduction de graphe na’ve
Implķmenter la rķduction de graphe est assez simple,
mais ne doit pas Ļtre fait trop na’vement.
En effet,
la ![]() -rķduction duplique la reprķsentation du membre gauche du
-rķduction duplique la reprķsentation du membre gauche du
![]() -rķdex*,
car celui-ci peut Ļtre utilisķ dans d'autres termes.
C'est par exemple le cas lorsqu'une fonction est appliquķe Ó plusieurs jeux
d'arguments :
il ne faut pas que l'ķvaluation de la premiĶre application change la
valeur de la fonction.
La figure 2 illustre la rķduction de graphe
et la duplication du membre gauche du
-rķdex*,
car celui-ci peut Ļtre utilisķ dans d'autres termes.
C'est par exemple le cas lorsqu'une fonction est appliquķe Ó plusieurs jeux
d'arguments :
il ne faut pas que l'ķvaluation de la premiĶre application change la
valeur de la fonction.
La figure 2 illustre la rķduction de graphe
et la duplication du membre gauche du ![]() -rķdex.
Dans cette figure et dans les suivantes,
les
-rķdex.
Dans cette figure et dans les suivantes,
les ![]() sont des objets de la reprķsentation.
Les parties gauche et droite de la figure schķmatisent respectivement
l'ķtat de la reprķsentation avant et aprĶs la
sont des objets de la reprķsentation.
Les parties gauche et droite de la figure schķmatisent respectivement
l'ķtat de la reprķsentation avant et aprĶs la
![]() -rķduction.
Les objets
-rķduction.
Les objets ![]() ,
, ![]() et
et ![]() restent inchangķs,
et c'est nķcessaire car ils peuvent Ļtre utilisķs dans d'autres contextes.
L'objet
restent inchangķs,
et c'est nķcessaire car ils peuvent Ļtre utilisķs dans d'autres contextes.
L'objet ![]() est transformķ.
Il contient initialement une notation d'application,
et donc de
est transformķ.
Il contient initialement une notation d'application,
et donc de ![]() -rķdex puisque son membre gauche est une
-rķdex puisque son membre gauche est une ![]() -abstraction.
AprĶs la
-abstraction.
AprĶs la ![]() -rķduction,
il contient une copie de l'objet
-rķduction,
il contient une copie de l'objet ![]() o∙ les
occurrences de la variable x sont remplacķes par une rķfķrence Ó l'objet
o∙ les
occurrences de la variable x sont remplacķes par une rķfķrence Ó l'objet
![]() .
C'est ce remplacement qu'on ne peut pas effectuer dans l'original car celui-ci
doit pouvoir resservir.
.
C'est ce remplacement qu'on ne peut pas effectuer dans l'original car celui-ci
doit pouvoir resservir.
On peut observer que si on sait que ![]() ne contient pas d'occurrences de
la variable x,
la procķdure de remplacement ne risque pas de modifier
ne contient pas d'occurrences de
la variable x,
la procķdure de remplacement ne risque pas de modifier ![]() :
on peut donc le partager plut¶t que le dupliquer.
La figure 3 illustre cette possibilitķ
dans le cas dķgķnķrķ o∙ la variable x n'a pas d'occurrences dans
:
on peut donc le partager plut¶t que le dupliquer.
La figure 3 illustre cette possibilitķ
dans le cas dķgķnķrķ o∙ la variable x n'a pas d'occurrences dans ![]() .
La situation gķnķrale est celle o∙
.
La situation gķnķrale est celle o∙ ![]() contient des occurrences de la
variable x et des sous-termes sans occurrences de x
(voir la figure 4).
On veut alors dupliquer la partie de
contient des occurrences de la
variable x et des sous-termes sans occurrences de x
(voir la figure 4).
On veut alors dupliquer la partie de ![]() qui contient les occurrences
de x et partager les autres sous-termes.
Dans la figure,
ces sous-termes sont schķmatisķs par l'objet
qui contient les occurrences
de x et partager les autres sous-termes.
Dans la figure,
ces sous-termes sont schķmatisķs par l'objet ![]() .
.
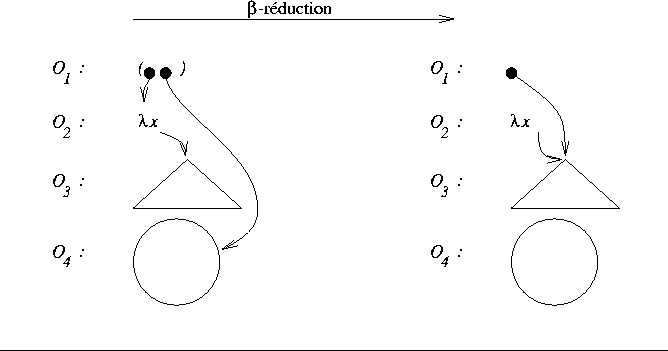
Figure 3: Rķduction de graphe avec partage de combinateurs (cas dķgķnķrķ)
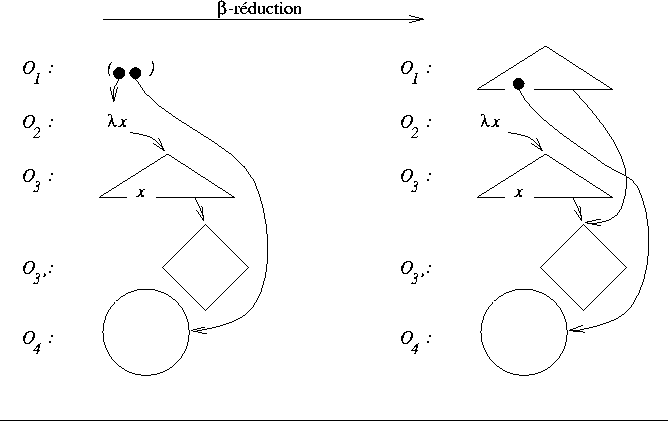
Figure 4: Rķduction de graphe avec partage de combinateurs (cas gķnķral)
Puisque le co¹t d'une exploration et le co¹t d'une duplication sont
similaires,
on ne gagnerait rien Ó dķtecter l'absence d'occurrence de la variable Ó
substituer Ó chaque ![]() -rķduction par une exploration.
Il faut donc trouver un moyen de connaŅtre les
-rķduction par une exploration.
Il faut donc trouver un moyen de connaŅtre les ![]() -variables
contenues libres dans un terme, sans avoir Ó l'explorer.
Noter exactement et sans explorations rķpķtķes
cette information dans chaque sous-terme est impossible car ce n'est pas
une propriķtķ stable par instanciation et
-variables
contenues libres dans un terme, sans avoir Ó l'explorer.
Noter exactement et sans explorations rķpķtķes
cette information dans chaque sous-terme est impossible car ce n'est pas
une propriķtķ stable par instanciation et ![]() -rķduction.
Cependant,
il existe une approximation de cette propriķtķ
qui est stable par instanciation et
-rķduction.
Cependant,
il existe une approximation de cette propriķtķ
qui est stable par instanciation et ![]() -rķduction :
c'est le fait qu'un terme ne contient aucune
-rķduction :
c'est le fait qu'un terme ne contient aucune
![]() -variable libre.
Un tel terme est un combinateur*,
et une marque binaire suffit Ó le noter.
Elle est calculķe dĶs la compilation,
et ensuite propagķe par des rĶgles simples
aux termes qui se construisent Ó l'exķcution.
Ce faisant,
on renonce Ó partager tout ce qui peut l'Ļtre,
et on ķvite de dupliquer uniquement les termes qui ne contiennent aucune
variable libre au lieu de ceux qui ne contiennent aucune occurrence libre
de la variable Ó substituer.
-variable libre.
Un tel terme est un combinateur*,
et une marque binaire suffit Ó le noter.
Elle est calculķe dĶs la compilation,
et ensuite propagķe par des rĶgles simples
aux termes qui se construisent Ó l'exķcution.
Ce faisant,
on renonce Ó partager tout ce qui peut l'Ļtre,
et on ķvite de dupliquer uniquement les termes qui ne contiennent aucune
variable libre au lieu de ceux qui ne contiennent aucune occurrence libre
de la variable Ó substituer.
On peut se demander si cette approximation n'est pas trop grossiĶre.
En fait, il n'en est rien,
et c'est lÓ que la comprķhension de
l'implķmentation et celle du langage s'enrichissent mutuellement.
L'idķe est qu'il y a ķnormķment de combinateurs lors de
l'exķcution simplement parce qu'ils constituent le ½vrai╗
domaine de calcul de ![]() Prolog.
En effet,
les variables logiques ne peuvent Ļtre instanciķes que par des combinateurs,
et il n'y a pas de
Prolog.
En effet,
les variables logiques ne peuvent Ļtre instanciķes que par des combinateurs,
et il n'y a pas de
![]() -variables* libres dans une formule logique.
Cela a deux consķquences :
une pour l'implķmenteur et une autre pour le programmeur.
-variables* libres dans une formule logique.
Cela a deux consķquences :
une pour l'implķmenteur et une autre pour le programmeur.
Au niveau du schķma d'exķcution, la consķquence est que se limiter Ó reconnaŅtre les combinateurs plut¶t que les occurrences libres de chaque variable dans chaque sous-terme est un bon compromis. Par exemple, dans le cadre d'une reprķsentation fonctionnelle* des listes, le prķdicat de renversement de liste a la forme suivante :
type ((list A)->(list A)) -> ((list A)->(list A)) -> o .
renv x
renv x![]() x y
x y![]() y .
y .
![]() [A | (L x)] y
[A | (L x)] y![]() (R [A | y]) :- renv L R .
(R [A | y]) :- renv L R .
Nous avons choisi de donner des noms diffķrents aux diffķrentes
![]() -variables
liķes dans une mĻme clause pour pouvoir les dķsigner par leur nom dans le
commentaire.
Cela n'est absolument pas nķcessaire en
-variables
liķes dans une mĻme clause pour pouvoir les dķsigner par leur nom dans le
commentaire.
Cela n'est absolument pas nķcessaire en
![]() Prolog.
Au contraire,
nous recommandons de donner systķmatiquement le mĻme nom aux variables
qui jouent le mĻme r¶le.
Prolog.
Au contraire,
nous recommandons de donner systķmatiquement le mĻme nom aux variables
qui jouent le mĻme r¶le.
Dans la seconde clause, la variable logique A ne peut dķsigner qu'un combinateur, et en particulier, elle ne peut contenir d'occurrence libre ni de y ni de x. Cette variable reprķsente un ķlķment d'une liste fonctionnelle, et rķcursivement toute la liste est constituķe d'ķlķments qui sont des combinateurs. Ainsi, lorsque la liste R est appliquķe Ó [A|y], seul son squelette devra Ļtre dupliquķ.
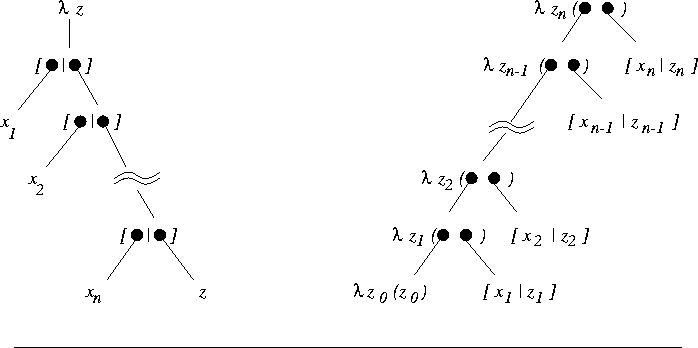
Figure: Listes fonctionnelles peignķes : Ó droite, Ó gauche
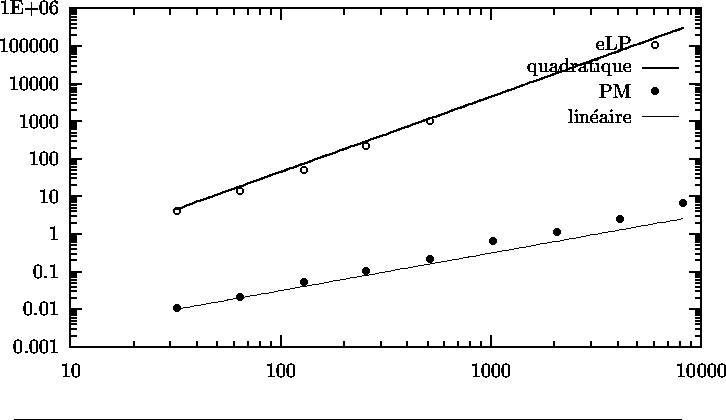
Figure: Comparaison de temps de calcul pour renverser une liste fonctionnelle, sun4, 32 Mo (longueur de la liste ![]() temps de calcul en secondes, ķchelle log-log)
temps de calcul en secondes, ķchelle log-log)
Mieux,
grŌce Ó la paresse du ![]() -rķducteur,
la liste R a la forme
de
-rķducteur,
la liste R a la forme
de
![]()
plut¶t que de
![]() .
En d'autres termes,
elle est peignķe Ó gauche par des applications au lieu d'Ļtre peignķe Ó droite
par des constructeurs
(voir la figure 5).
Tout ce qui est soulignķ est un combinateur
car c'est une instance de la variable logique R au rang n-1.
On voit donc qu'Ó chaque itķration
.
En d'autres termes,
elle est peignķe Ó gauche par des applications au lieu d'Ļtre peignķe Ó droite
par des constructeurs
(voir la figure 5).
Tout ce qui est soulignķ est un combinateur
car c'est une instance de la variable logique R au rang n-1.
On voit donc qu'Ó chaque itķration![]() le rķdex du second argument de renv ne nķcessite de dupliquer qu'une
application et un cons.
On obtient ainsi des amķliorations de complexitķ,
et on atteint mĻme dans cet exemple la complexitķ linķaire attendue
(voir la figure 6 et
[Brisset et Ridoux 91, Brisset et Ridoux 94]).
Les deux axes de la figure 6 utilisent une ķchelle logarithmique.
Cela permet de reprķsenter des ķcarts d'amplitude trĶs grands,
et de visualiser la complexitķ effective des calculs de
le rķdex du second argument de renv ne nķcessite de dupliquer qu'une
application et un cons.
On obtient ainsi des amķliorations de complexitķ,
et on atteint mĻme dans cet exemple la complexitķ linķaire attendue
(voir la figure 6 et
[Brisset et Ridoux 91, Brisset et Ridoux 94]).
Les deux axes de la figure 6 utilisent une ķchelle logarithmique.
Cela permet de reprķsenter des ķcarts d'amplitude trĶs grands,
et de visualiser la complexitķ effective des calculs de ![]() et
et ![]() en comparant simplement les pentes de deux droites
(1 pour linķaire, 2 pour quadratique).
en comparant simplement les pentes de deux droites
(1 pour linķaire, 2 pour quadratique).
Tout ceci rķsulte d'une analyse purement locale.
Une analyse globale permettrait de dķtecter que tout ou partie du corps d'une
![]() -abstraction n'est de toute fańon pas utilisķ ailleurs que dans ce
-abstraction n'est de toute fańon pas utilisķ ailleurs que dans ce
![]() -rķdex et qu'on peut donc le modifier in-situ sans risque.
C'est un champ de recherche en cours d'exploration
[Malķsieux et al. 98].
-rķdex et qu'on peut donc le modifier in-situ sans risque.
C'est un champ de recherche en cours d'exploration
[Malķsieux et al. 98].
L'autre consķquence de ce qu'il n'y a pas de
![]() -variables* libres dans une formule logique
se situe au niveau de la programmation :
on ne peut pas ½parler╗
-variables* libres dans une formule logique
se situe au niveau de la programmation :
on ne peut pas ½parler╗![]() directement de termes qui ne sont pas des combinateurs.
Or,
on a besoin de ½parler╗ de termes contenant des variables libres,
ne serait-ce que pour exprimer une propriķtķ par induction sur
la structure des
directement de termes qui ne sont pas des combinateurs.
Or,
on a besoin de ½parler╗ de termes contenant des variables libres,
ne serait-ce que pour exprimer une propriķtķ par induction sur
la structure des ![]() -termes
(
-termes
(![]() induction structurelle*).
Un combinateur qui est une abstraction
peut avoir des sous-termes qui ne sont pas des combinateurs.
C'est mĻme le cas le plus frķquent car autrement ce serait
une abstraction triviale qui n'utiliserait pas les variables qu'elle lie.
Le moyen de parler de termes avec
induction structurelle*).
Un combinateur qui est une abstraction
peut avoir des sous-termes qui ne sont pas des combinateurs.
C'est mĻme le cas le plus frķquent car autrement ce serait
une abstraction triviale qui n'utiliserait pas les variables qu'elle lie.
Le moyen de parler de termes avec ![]() -variables libres sans jamais en
citer explicitement est fourni par une correspondance trĶs importante
entre
-variables libres sans jamais en
citer explicitement est fourni par une correspondance trĶs importante
entre ![]() -abstraction et quantification universelle dans les buts :
ce sont toutes deux des
quantifications essentiellement universelles*.
En utilisant cette correspondance,
les constantes
universelles reprķsentent les
-abstraction et quantification universelle dans les buts :
ce sont toutes deux des
quantifications essentiellement universelles*.
En utilisant cette correspondance,
les constantes
universelles reprķsentent les ![]() -variables libres, mais n'en sont pas.
Cela permet de reprķsenter des termes avec
-variables libres, mais n'en sont pas.
Cela permet de reprķsenter des termes avec ![]() -variables libres
par des combinateurs.
-variables libres
par des combinateurs.