|
|
|
Sommaire |
Le but d’un module de compréhension est d’extraire le sens d’un signal de parole, afin d’interagir avec
l’utilisateur. Actuellement, seuls les systèmes restreints à des domaines limités peuvent être conçus à
avoir la faculté de comprendre le sens des paroles de l’utilisateur. Seule cette restriction autorise la
création de modèles de langage contraints spécifiques et d’une description sémantique complète
permettant une robustesse suffisante à la création d’un système utilisable. Pour réaliser cette opération,
il existe des méthodes manuelles ([Minker et Bennacef, 1996]) ou des approches stochastiques
([Pieraccini et Levin, 1993, Schwartz et al., 1997, Riccardi et Gorin, 1998]) qui ont permis
de réduire fortement le recours à l’expertise humaine lors du développement du module de
compréhension.
Du point de vue pragmatique, le but du module de compréhension est de transformer le signal de parole en une structure sémantique qui sera utilisée par le gestionnaire de dialogue pour décider de l’action à entreprendre. Une définition précise d’une structure sémantique n’est pas ici quelque chose de critique. On peut la définir simplement comme une structure d’informations représentant une intention associée à des objets représentés sous la forme d’une paire attribut/valeur. Ces objets seront nommés concepts. Par exemple, le système PlanResto (présenté en section 4.2) de recherche de restaurant pourrait dire :
et l’utilisateur peut répondre :
Dans ce cas la structure sémantique Γ pourrait ressembler à :
| [Recherche | Restaurant :] |
| [spécialité]→(japonais) | |
| [lieu]→(Bastille) | |
| [prix]→() | |
Le principe d’interprétation consiste donc à détecter les segments correspondants aux paires
attribut/valeur et à en déduire la représentation sémantique.
Certaines erreurs ont pu être commises, aux composants de cette structure peuvent être alors associés différents niveaux de confiance. En fonction de la structure sémantique décodée, de l’état actuel du dialogue, le gestionnaire de dialogue peut générer une structure sémantique encodant, par exemple, une requête pour confirmer un concept et obtenir le prix.
L’analyseur sémantique d’un système de dialogue, qui aboutit à une compréhension, constitue la phase primordiale du traitement. Un tel module doit être capable de fournir une représentation du sens en dépit des difficultés inhérentes à la parole spontanée. En effet, le langage parlé de nature spontanée se manifeste par des répétitions, des hésitations ou des requêtes disloquées (ruptures de construction) qui ne respectent pas la grammaire de l’écrit. De plus les erreurs de reconnaissance du module RAP peuvent aggraver la situation. C’est pourquoi un analyseur robuste est nécessaire. Bien que l’interprétation sémantique puisse être obtenue à partir d’une analyse syntaxique [Roark, 2002, Chappelier et al., 1999], l’extraction sémantique ne s’appuie généralement pas totalement sur l’analyse syntaxique telle qu’elle est menée par des grammaires de type hors-contexte ; elle se limite la plupart du temps aux éléments porteurs de sens de la requête tout en ignorant les parties redondantes ou non-essentielles pour l’application.
Des grammaires hors-contexte peuvent être utilisées pour analyser une phrase complète,
par exemple la phrase « je veux aller à Marseille » pourrait être analysée par la grammaire
suivante :
| (a) | S | → | NP VP |
| (b) | NP | → | N |
| (c) | VP | → | Vcluster PP |
| (d) | Vcluster | → | veux V |
| (e) | V | → | aller | voyager |
| (f) | PP | → | prep NP |
| (g) | N | → | Marseille | je |
| (h) | prep | → | à |
| à Marseille. |
| je vais à Marseille. |
| je suis en retard, j’ai un congrès dans Marseille. |
| je veux partir d’Avignon et joindre Marseille demain. |
| ... |
Ces phrases présentent différents types de variations pour lesquels une grammaire qui couvre toute la
phrase peut avoir des problèmes d’analyse. C’est pourquoi les concepteurs de systèmes de dialogue ont
gravité autour de l’idée d’analyse robuste. L’analyse robuste est l’idée d’extraire seulement les morceaux
porteurs d’un sens basique (que nous nommerons concepts) d’une phrase, en ignorant le reste. Des petites
grammaires peuvent être écrites pour analyser une phrase, voire un graphe de mots, afin de rechercher
seulement les unités pour lesquelles elles sont spécialisées. Par exemple, une grammaire Destination, peut
parcourir toutes les différentes séquences précédentes et trouver la destination dans chaque cas :
| Destination | → | Préposition NomVille |
| Préposition | → | à | dans | joindre |
| NomVille | → | Marseille | ... |
Pour en savoir davantage, on peut se référer à [Huang et Hon, 2001].
Un premier effort considérable dans la compréhension du langage parlé (SLU) a été effectué avec le projet DARPA qui a débuté en 1971. Le projet est passé en revue dans [Klatt, 1977]. Un nouveau projet DARPA débuté dans les années 90 dans le domaine des systèmes d’informations de voyage aérien (ATIS : Air Travel Information System) a réussi brillamment à accélérer le développement de systèmes SLU en se focalisant sur des tâches d’accès à des bases de données qui n’étaient pas trop éloignées des scénarios concrets. Les systèmes développés dans ce projet ainsi que les approches précédentes sur la compréhension du langage naturel sont passés en revue dans [Kuhn et De Mori, 1998]. Les sections suivantes présentent quelques approches classiquement utilisées.
[Minker et Bennacef, 1996] utilisent le formalisme de la grammaire des cas [Fillmore, 1968] pour construire une représentation sémantique sous forme d’un schéma. Le concept du schéma est identifié par un ou plusieurs mots de référence dans la phrase. Les attributs du schéma sont instanciés à partir de certaines parties de la phrase en utilisant des contraintes syntaxiques locales sous forme de marqueurs. Un schéma incomplet peut toutefois être complété par d’autres schémas à l’aide du gestionnaire de dialogue. Le processus de l’analyse considère seulement certaines parties de la phrase comme étant sémantiquement significatives. Les hésitations et les répétitions, par exemple, sont ignorées. Dans un premier temps, est alors appliqué un post-traitement sur la transcription, qui associe aux mots leur version de base (lemme par exemple) et les mots sémantiquement reliés sont regroupés (entités nommées). Les mots non-porteurs d’informations ou hors domaine sont assignés à une catégorie spéciale notée filler.
L’analyse sémantique procède alors de la manière suivante (considérant la représentation schématique dans le tableau 2.1 sur une application qui fournirait un service de consultation d’horaires d’avion) : au niveau conceptuel, les MOTS DE RÉFÉRENCE permettent de sélectionner le SCHÉMA correspondant ; ensuite, les parties variables du schéma, ici introduites par le symbole @, sont instanciées en utilisant des marqueurs, sachant que des structures de niveau plus élevé font référence à des SOUS-SCHÉMAs de niveau inférieur. Le niveau intermédiaire abrite les relations entre les marqueurs et les attributs. Le SOUS-SCHÉMA itinéraire, par exemple, contient les attributs @Départ et @Destination. Les mots appartenant à ces attributs doivent être précédés de « de, départ » et « à, destination » respectivement. Le niveau de base regroupe la liste des attributs autorisés, par exemple les SOUS-SCHÉMAs ville et heure. Ils correspondent principalement aux valeurs dans la base de données. Pour chaque mot de la phrase, l’analyseur sémantique est appliqué de manière successive sur les SCHÉMAs et les SOUS-SCHÉMAs jusqu’à ce qu’il n’y ait plus de mots qui puissent remplir les champs du schéma. Une fois complété, le schéma sémantique représente le sens de la phrase.
|
L’entrée du Template Matcher (TM) est la meilleure hypothèse de mots générée par le module de reconnaissance de la parole, qui utilise un modèle de langage Bi-grammes [Appelt et Jackson, 1992]. Le TM tente simplement de remplir les champs d’une structure sémantique. Les différentes structures sont en compétition avec les autres sur chaque intervention ; à toutes, est associé un score ; et la structure avec le meilleur score génère la requête à la base de données. Les champs sont remplis en cherchant dans l’énoncé certaines séquences de mots. Le score d’une structure est simplement le pourcentage de mots de l’énoncé qui contribue à la remplir. Cependant, certains mots-clefs qui sont fortement corrélés avec une structure particulière augmentent fortement son score s’ils apparaissent. Si le meilleur score n’excède pas un seuil défini, le système préfère ne pas répondre plutôt que de faire confiance à cette structure.
DELPHI est un analyseur linguistique qui génère les N-meilleures hypothèses en utilisant un algorithme simple et rapide [Schwartz et al., 1992], qui re-score répétitivement ces hypothèses au moyen d’un algorithme plus complexe et plus lent. De cette manière, plusieurs sources de connaissances peuvent contribuer au résultat final sans compliquer la structure de contrôle ou ralentir significativement la production du résultat final.
La première version de DELPHI consiste en un analyseur basé sur des schémas. Un dispositif intéressant de cet analyseur, a été l’incorporation de probabilités pour les différents sens d’un mot et pour l’application de règles grammaticales. Ces probabilités sont estimées à partir de données et utilisées pour réduire l’espace de recherche pour l’analyse. Un module de repli a été incorporé dans les versions suivantes. Un analyseur syntaxique utilise des règles étendues pour générer une analyse complète de l’énoncé. S’il échoue, un analyseur tente de remplir les champs de la structure à la manière du Template Matcher.
En beaucoup de points, le système Phoenix de l’université de Carnegie Mellon (CMU) est similaire au Template Matcher du SRI [Issar et Ward, 1994]. Le principe d’interprétation consiste à détecter les segments correspondant aux concepts (paires attribut/valeur) et à en déduire le schéma. Il n’y a pas de grammaire globale, mais plusieurs sous-grammaires dont chacune est associée à un concept. Le score pour un schéma est simplement le nombre de mots dans l’énoncé pris en compte.
L’analyseur linguistique TINA développé à l’institut technologique du Massachusetts (MIT), a connu la même évolution que d’autres analyseurs linguistiques : il consistait au départ en un analyseur syntaxique global. Cette analyse utilise une grammaire hors-contexte transformée de façon automatique en un automate portant des probabilités sur les arcs, ce qui permet d’avantager les constructions les plus courantes. Les nœuds de cet automate font référence à des catégories particulières, qui peuvent être sémantiques (comme les lieux) ou bien syntaxiques (par exemple les verbes ou les adjectifs) [Seneff, 1989]. Un analyseur robuste a été ajouté qui intervient lorsque il échoue [Seneff, 1992]. Il est obtenu en modifiant la grammaire autorisant des analyses partielles. Dans ce mode, l’analyseur effectue un traitement gauche-droite comme d’habitude, mais un ensemble exhaustif des analyses possibles est généré commençant à chaque mot de l’énoncé. L’aspect inhabituel de cet analyseur robuste est qu’il exploite l’historique du dialogue en autorisant les champs du schéma à être hérités des énoncés précédents.
Le système CHRONUS (Conceptual Hidden Representation of Natural Unconstrained Speech) est un système de compréhension de la parole développé par le laboratoire AT&T [Pieraccini et Levin, 1995] qui propose un décodage conceptuel stochastique. Ce système considère l’énoncé utilisateur comme une séquence de concepts élémentaires. Ces concepts sont des séquences de mots correspondant à des unités de sens. Le rôle du décodage conceptuel consiste à découper l’énoncé en concepts. Le processus suit un modèle Markovien dont les états sont les concepts. La séquence de mots relative à un concept est aussi modélisée par un processus Markovien représenté par un modèle de langage N-grammes conditionné sur les concepts.
Le système CHANEL [Kuhn et De Mori, 1995] est le résultat d’une recherche conduite à l’université Mc Gill de Montréal. CHANEL apprend des règles de détection de concepts au moyen de plusieurs arbres de décisions spécialisés appelés arbre de classification sémantique (SCTs). Il y a un SCT pour chaque concept. L’aspect le plus intéressant de CHANEL est que les SCTs tentent de découvrir des règles faisant intervenir aussi peu de mots ou d’unités syntaxiques que possible. Ils sont donc tolérants à un haut degré d’erreurs de reconnaissance sur les mots sémantiquement non-importants. Une autre différence importante entre CHANEL et les systèmes comme CHRONUS, est que CHRONUS fait une correspondance entre morceau de phrase et concept, tandis que chaque SCTs dans CHANEL utilise la phrase entière pour déterminer les concepts. Cela permet qu’un mot ou plusieurs mots contribuent à plus d’un concept.
Le hidden understanding model (HUM) [Miller et al., 1994] propose la technique suivante. Soit W la chaîne de mots et S la représentation sémantique associée. En accord avec la règle de Bayes nous avons :
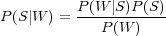 | (2.1) |
La tâche du processus d’interprétation revient alors à trouver la représentation sémantique Ŝ, telle que :
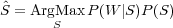 | (2.2) |
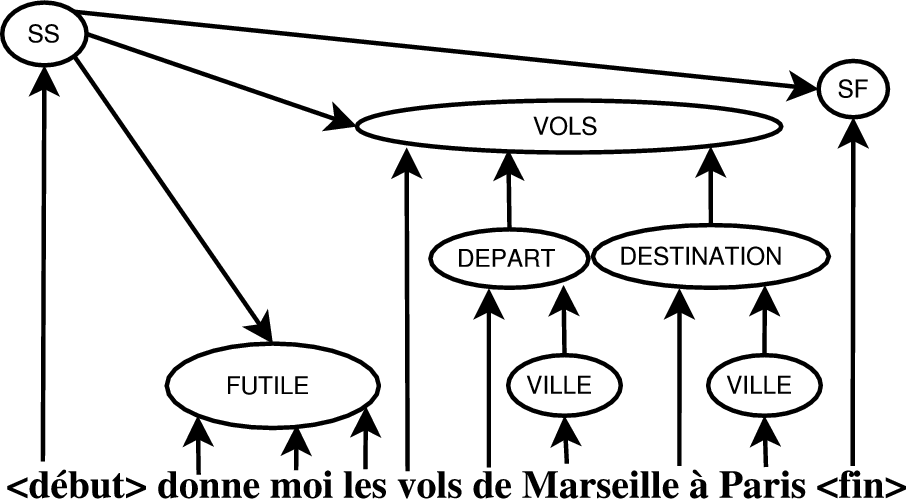
P(S) est le modèle de langage sémantique qui détermine la distribution statistique a priori de la représentation sémantique. Il est basé sur une représentation sémantique en forme d’arbre où les concepts sont les nœuds et les sous-concepts sont les nœuds fils (le tableau 2.2 illustre cette représentation pour la phrase « donne moi les vols de Marseille à Paris »).
|
Le concept VOL possède les sous-concepts Vol_Indice,Origine,Destination. Les sous-concepts Destination et Origine contiennent respectivement les nœuds terminaux Destination_Indice, Ville ; Origine_Indice Ville. Chaque nœud terminal peut être composé d’un où plusieurs mots.
Le modèle de langage sémantique P(S) est modélisé comme P(Si|Si−1,concept) où concept est le concept parent pour Si et Si−1. Basé sur cette définition, la probabilité P(Destination|Origine,V ol) est plus grande que la probabilité P(Origine|Destination,V ol), les utilisateurs d’un système de réservation d’avions omettant souvent de préciser l’origine du vol. P(W|S) est lui appelé modèle de réalisation lexicale, c’est basiquement un modèle Bi-grammes de mots enrichi avec le contexte du concept parent :
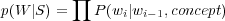 | (2.3) |
Le modèle de langage sémantique ainsi que le modèle de réalisation lexicale sont appris sur un corpus étiqueté. L’algorithme de Viterbi est appliqué pour trouver le meilleur chemin correspondant à l’interprétation sémantique Ŝ en accord avec l’équation 2.2.
[He et Young, 2003] proposent pour le processus d’analyse sémantique un modèle vectoriel à états cachés (hidden vector state model HVS). Le principe est le suivant : si l’on considère l’arbre d’analyse de la figure 2.1, l’information sémantique reliée à chaque mot seul peut être codée en tant qu’un vecteur d’étiquettes sémantiques en partant de l’étiquette pré-terminale et finissant à l’étiquette racine. Par exemple le mot Marseille est décrit par le vecteur sémantique [V ILLE,DEPART,V OLS,SS] et l’arbre complet d’analyse peut être remplacé par une séquence de vecteurs telle que l’illustre le tableau 2.3. En prenant chaque vecteur d’état comme une variable cachée, l’arbre d’analyse peut être traité comme un processus markovien, ceci est le modèle HVS.
|
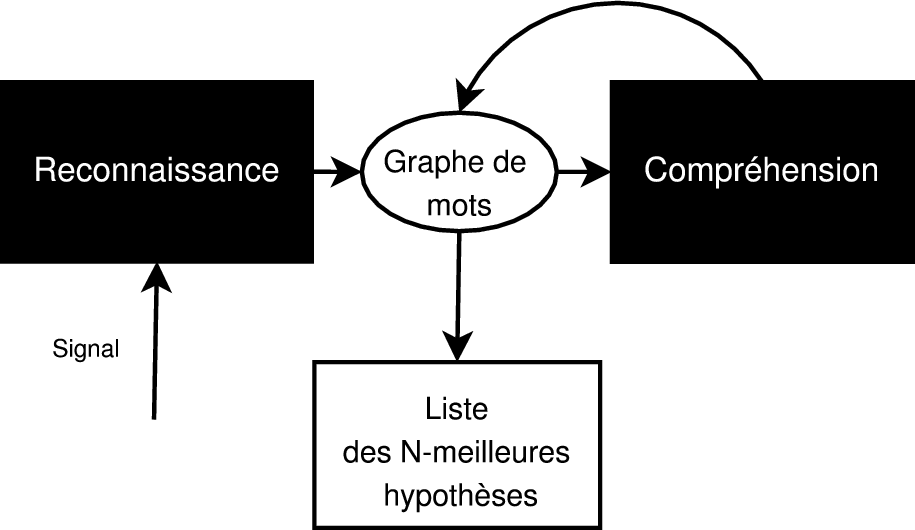
Le processus de compréhension se fait généralement en deux temps : la génération d’une transcription du signal de parole en unités linguistiques (mots ou phrase) suivie de l’analyse de cette transcription. Certains travaux font intervenir les connaissances nécessaires à la compréhension dans le processus de transcription. Deux approches existent : la première, propose une architecture en deux passes où les informations de compréhension sont utilisées sur le graphe de mots issu du module RAP (2.3) ; la seconde, utilise une architecture de reconnaissance en une passe, où les informations de compréhension sont utilisées pour guider le processus de transcription (figure 2.2).
|
|
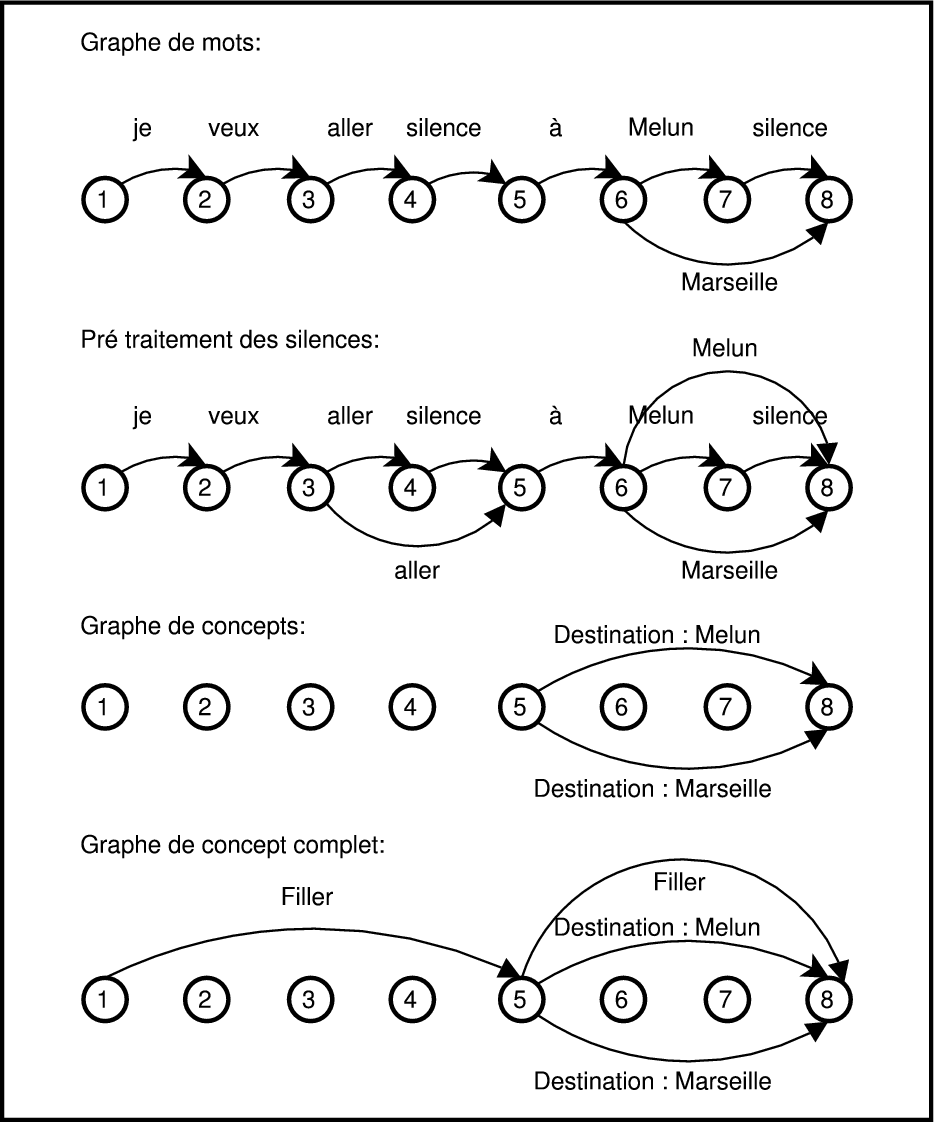
La première architecture peut être illustrée par le processus de compréhension du système Philips [Aust et al., 1995] qui travaille directement sur le graphe de mots proposé par le module RAP.
Les considérations suivantes sont utilisées : le sens de l’intervention utilisateur est exprimé par des séquences de mots significatives appelées concepts. Ces concepts s’agencent d’une manière arbitraire et des mots inutiles pour le processus de compréhension peuvent s’intercaler entre deux concepts. Ces mots inutiles sont désignés par « filler » .
Le traitement est réalisé en 4 étapes (voir figure 2.4) :
Si le processus de transcription suit le principe statistique de l’équation 1.3, dans un système de dialogue, c’est le sens (S) de l’intervention utilisateur qui doit être trouvé. Étant donné un signal de parole A le problème de compréhension revient à chercher pour :
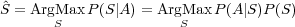 | (2.4) |
Il est en général plus pratique de transcrire d’abord le signal A en unités linguistiques (mot ou phrase) pour que l’extraction sémantique soit réalisable :
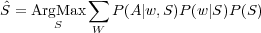 | (2.5) |
Bien que le modèle acoustique P(A|w,S) dans une application de dialogue peut être dynamiquement ajusté en fonction du contexte du dialogue, la plupart des systèmes considèrent que les statistiques acoustiques sont satisfaisantes étant donné l’événement linguistique : P(A|w,S) ≃ P(A|w). [Wang, 2003] considère que le modèle de langage sémantique P(w|S) et le processus de décodage réalisant le ArgMax dans l’équation précédente est la clef pour articuler les processus de transcription et de compréhension. La différence entre un modèle de langage P(w) et un modèle de langage sémantique P(w|S) est que le second prend en considération l’hypothèse sémantique S pour prédire la séquence de mots, guidant le processus de transcription vers une chaîne de mots plus pertinente pour le processus de compréhension.
Pour incorporer les structures sémantiques dans le modèle de langage sémantique P(w|S), [Wang, 2003] emploie une technique de modèle de langage unifié (ULM) qui combine des grammaires hors-contexte probabilistes (PCFG) avec des N-grammes. Les PCFG et les N-grammes ont des qualités et des défauts complémentaires, de nombreuses tentatives ont été faites pour combiner ces approches de modélisation en une seule cohérente appelée modèle de langage unifié (ULM). Une approche très utilisée en reconnaissance de la parole (par exemple [Riccardi et al., 1996, Nasr et al., 1999]) permet d’étendre la notion de classe dans les N-grammes à base de classes en associant à un mot une séquence de mots modélisés par une PCFG. Par exemple pour l’exemple : « Un prix de cent francs soit trente deux pourcent de moins », un Tri-gramme aurait à calculer les probabilités comme P(francs|de cent) et P(trente|francs soit) alors qu’un ULM a à traiter la phrase « Un prix de Prix soit Pourcentage de moins » et considère les probabilités P(Prix|prix de) et P(Pourcentage|Prix soit). Ce type d’ULM permet de réduire la perplexité pour le modèle de langage de reconnaissance, mais n’est pas forcément adapté pour découvrir la structure sémantique d’une phrase.
[Wang, 2003] utilise une seconde méthode permettant d’encapsuler des N-grammes dans des PCFG. Les symboles non-terminaux de la grammaire peuvent être modélisés par des N-grammes et notamment les symboles pré-terminaux. Avec cette approche, il est possible de garder la trace des règles invoquées dans les PCFG pour découvrir la structure de la phrase. Si les règles sont écrites pour refléter la construction d’une structure sémantique de l’application, le résultat est alors un arbre qui représente le sens de la phrase. Ce type de combinaison est désigné par « ULM pour la compréhension ». Tandis que les PCFG seules sont utilisées pour l’extraction sémantique, cet ULM est utile pour élargir la couverture lexicale grâce à la flexibilité des N-grammes.
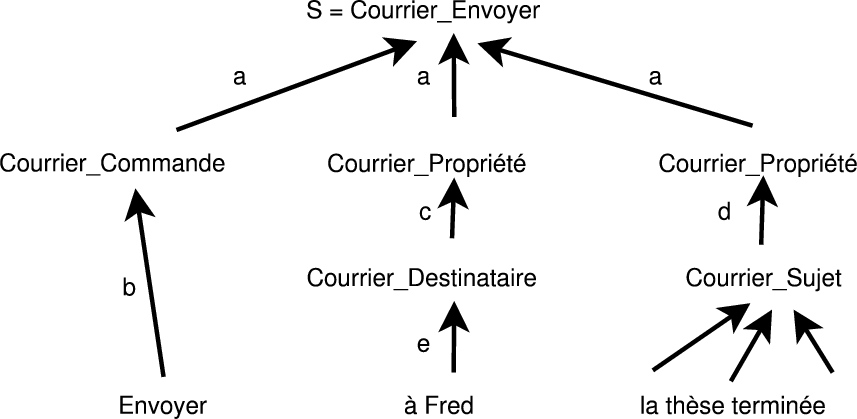
La figure 2.5 illustre l’analyse sémantique de la phrase w =« Envoyer à Fred la thèse terminée ». Les règles de la grammaire amenant à l’interprétation S (Envoyer Courrier) sont les suivantes :
Dans cet exemple, seul le pré-terminal Courrier_Sujet est couvert par des N-grammes. La probabilité de la chaîne w sachant l’interprétation S, P(w|S) est le produit des N-grammes pour P(la thèse terminée|Courrier_Sujet) et les probabilités de toutes les règles listées précédemment. Les N-grammes peuvent aussi être utilisés pour modéliser toutes les expressions à droite des règles de la PCFG et pas seulement les pré-terminaux comme dans l’exemple précédent. L’architecture de décodage proposée en utilisant ce modèle permet de pouvoir séquentiellement au fur et à mesure du décodage de repérer des hypothèses sémantiques et de prédire les objets sémantiques suivants afin de construire une structure sémantique complète.