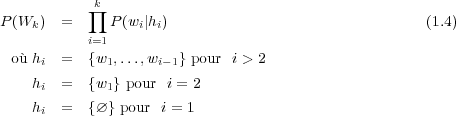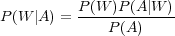
|
Sommaire |
La grande majorité des systèmes de reconnaissance automatique de la parole (RAP) fonctionne sur des principes probabilistes. Pour cela, à partir de la séquence d’observations acoustiques A = a1a2…am extraite du signal de parole, un système de reconnaissance de la parole recherche la séquence de mots Ŵ = w1w2...wk qui maximise la probabilité a posteriori P(W|A). Soit la probabilité que la séquence d’observations acoustiques A génère la séquence de mots W. Or cette probabilité n’est pas calculable en l’état. En effet, une même personne prononçant deux fois une phrase, ne génère pas deux signaux identiques. Il est alors difficile d’imaginer construire un corpus permettant de pouvoir estimer cette probabilité. Le théorème de Bayes permet de reformuler cette probabilité en :
|
| (1.1) |
La séquence de mot Ŵ est celle qui maximise le produit de l’équation 1.1, comme noté dans l’équation 1.2.
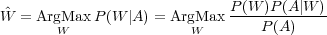 | (1.2) |
Or, dans ce produit la probabilité a priori de la séquence d’observations acoustiques P(A) n’est pas calculable pour les mêmes raisons que ne l’était pas P(W|A). Mais ici la séquence d’observations acoustiques A est identique pour toutes les hypothèses W, P(A) est une valeur constante qu’il est inutile de calculer pour trouver Ŵ. On a donc :
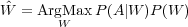 | (1.3) |
L’étape de reconnaissance revient a maximiser le produit des 2 termes, P(A|W) et P(W). P(A|W) est la probabilité qu’une séquence de mots W génère la séquence d’observations acoustiques A. Elle est estimée par un modèle acoustique. P(W) est la probabilité a priori de la séquence de mots, elle est estimée par un modèle de langage.
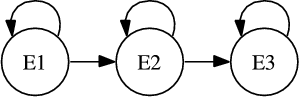
La fonction du modèle acoustique est d’estimer la première composante de l’équation 1.3. Étant donnée une séquence de vecteurs de paramètres extraits du signal de parole, le but des modèles acoustiques est de calculer la probabilité qu’un événement linguistique particulier (un mot, une phrase, etc.) ait généré cette séquence. La plupart des systèmes actuels recourent à l’utilisation des Modèles de Markov Cachés (HMMs). Les unités de base modélisées par ces systèmes sont souvent les phonèmes. L’utilisation de cette unité de base donne de bons résultats de reconnaissance, qui peuvent être améliorés en prenant en compte certaines caractéristiques des signaux de paroles. Il est connu que la réalisation d’un phonème est fortement influencée par les phonèmes qui l’entourent. Une description plus réaliste des sons de bases peut être effectuée en dédiant différents modèles au même phonème selon le contexte. Par exemple les modèles allophones ou Tri-phones. Un modèle de Markov peut être vu comme un automate stochastique. Les états sont associés à une densité de probabilité qui modélise les formes rencontrées P(Xk|Ei) qui est la probabilité de produire l’événement Xk sur l’état Ei. Les transitions assurent les contraintes d’ordre temporel des formes pouvant être observées. P(Ei+1|Ei) est la probabilité de transition d’un état à un autre. La figure 1.1 est un exemple de modèle pour les phonèmes. Les HMMs s’appuient sur un corpus d’apprentissage des différentes réalisations des phonèmes de la langue considérée pour les modéliser. Un modèle de mot peut alors être vu comme une concaténation successive de modèles de phonèmes, et la phrase complète comme une concaténation de modèles de mots. Les chemins dans cet automate représentent toutes les chaînes possibles de mots, le chemin ayant la plus forte probabilité est donc celui qui permet l’alignement optimal du signal acoustique sur le modèle de Markov. L’opération appelée décodage est celle qui permet de retrouver au mieux ce meilleur chemin. Différents algorithmes existent : Viterbi, le Beam Search, et le A∗.
De façon générale, on appelle langage un ensemble de conventions permettant de conceptualiser la pensée
et d’échanger avec d’autres interlocuteurs à l’aide d’un support comme la parole, l’écriture, etc. L’objectif
de la modélisation du langage est de trouver un moyen de le décrire. Deux grandes approches
existent : la modélisation basée sur l’utilisation de grammaires formelles mises au point par des
experts en linguistique et la modélisation stochastique qui tente de décrire automatiquement
un langage à partir de l’observation de corpus. Il est très difficile et long de représenter un
langage naturel de manière formelle. Dans le cadre d’applications de dialogue oral autorisant
l’utilisateur à s’exprimer librement, la modélisation stochastique du langage est privilégiée.
Les modèles de langage statistiques ont pour objectif d’estimer la seconde composante de l’équation 1.3.
En effet, le modèle acoustique n’a pas d’a priori sur l’enchaînement entre les mots. Il est relaté dans
[Mariani, 1990] qu’une suite de 9 phonèmes peut être transcrite en 32000 suites de mots différentes, dont
quelques unes seulement sont syntaxiquement correctes. Les modèles de langage vont permettre de
représenter des connaissances d’ordre linguistique afin de guider le décodage vers des hypothèses de
phrase cohérentes du point de vue syntaxique ou grammatical. Les modèles de langage statistiques
tentent alors de déterminer la probabilité a priori de la séquence de mots W = w1,w2,…,wk selon
l’équation 1.4.
Le principal problème dans l’utilisation de modèles de langage probabilistes tient en la longueur de l’historique considéré. En effet la taille des corpus d’apprentissage ne nous permet pas de calculer efficacement la probabilité P(wi|w1,w2,…,wi−1). On approche alors la probabilité en fonction d’un historique de taille réduite et fixe. C’est ce que l’on nomme un modèle N-grammes. Le calcul considère alors, pour la prédiction d’un mot, que la suite des N − 1 mots qui le précèdent est suffisante. Un N trop petit modélise mal les contraintes linguistiques tandis qu’un N trop grand va cruellement limiter la couverture du modèle. Les valeurs les plus utilisées sont N = 2 pour des modèles de langage appelé Bi-grammes et N = 3 pour des modèles de langage appelés Tri-gramme. Les termes de l’équation 1.4 pour un modèle Tri-gramme se résument alors à l’équation 1.5.
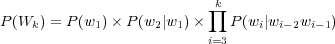 | (1.5) |
La probabilité d’apparition d’un mot est généralement estimée par le critère de maximum de vraisemblance. Pour un modèle Tri-gramme et pour un mot w précédé des mots wiwj cela donne :
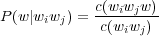
où c(wiwjw) correspond au nombre d’occurrences de la suite de mots wiwjw dans le corpus d’apprentissage et c(wiwj) au nombre d’occurrences de la suite de mots wiwj.
Le problème de cette modélisation est que les événements non-observés dans le corpus d’apprentissage du modèle ont une probabilité nulle. Afin de pallier le problème, plusieurs approches ont été développées pour pouvoir modéliser les événements qui n’ont pas été rencontrés lors de la phase d’apprentissage. Certaines utilisent des connaissances sur le langage pour générer des événements manquants, comme les modèles à base de classes (section 1.4), d’autres sont des techniques de lissage (section 1.5) dont les plus connues sont basées sur des méthodes de repli (back-off en anglais) sur des modèles N-grammes d’ordre inférieur.
La quantité de données nécessaire à l’apprentissage d’un modèle de langage robuste et performant, malgré l’utilisation de l’approximation N-grammes, reste importante. En partant du constat que certains mots ont un comportement similaire, il est possible de les regrouper en classes :
Dans ce cadre là, un mot wi appartient à une classe ci. Il est à noter qu’un mot peut très bien appartenir à plusieurs classes. Pour des raisons de simplicité, mettons qu’un mot wi n’appartient qu’à une seule classe ci, le modèle n-classes peut être construit à partir des n − 1 classes précédentes :
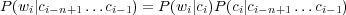 | (1.6) |
où P(wi|ci) est la probabilité du mot wi dans la classe ci et P(ci|ci−n+1…ci−1) est la probabilité de la classe ci connaissant l’historique des n− 1 classes précédentes. La probabilité d’une phrase W est donnée par :
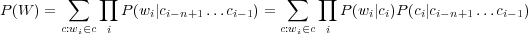 | (1.7) |
Si les classes ont une intersection vide, c’est à dire qu’à un mot ne correspond qu’une seule classe, et pour un modèle Tri-classes l’équation 1.7 peut être simplifiée en :
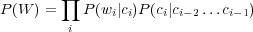 | (1.8) |
Si C(wi) est la fréquence du mot wi, C(ci) la fréquence de la classe ci et C(ci−1ci) la fréquence qu’un mot d’une classe soit suivi immédiatement d’un mot d’une autre classe, la probabilité Bi-grammes serait :
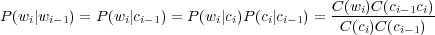 | (1.9) |
Un des problèmes important en modélisation stochastique du langage est que les corpus d’apprentissage ne couvrent pas toutes les successions de mots possibles. Ceci est encore plus vrai dans les applications de dialogue où les corpus sont de taille restreinte. De nombreux événements, des successions de mots possibles, ne sont pas observés. La probabilité qui leur est associée est alors nulle. Une chaîne de mots où apparaît un de ces événements n’est pas considérée comme une transcription potentielle et ceci sans considération de son score acoustique. Le but du lissage est de prévenir ces potentielles erreurs de reconnaissance en rendant la distribution observée plus uniforme en attribuant une probabilité non nulle à ces événements et en ajustant à la baisse les probabilités trop fortes. Les principales techniques sont détaillées dans [Chen et Goodman, 1996] où est également présentée une discussion sur leurs performances respectives.
L’estimation des paramètres d’un modèle de langage de type N-grammes est le plus souvent obtenue par la combinaison de deux composants : un modèle de discounting (décompte) et un modèle de redistribution. Le principe général est de prélever une quantité à la masse des probabilités issue des événements observés, et de la redistribuer aux probabilités associées aux événements non vus.
La probabilité d’un mot jamais vu en présence d’un historique donné est, sans lissage, nulle. Au contraire, les méthodes de lissage présentées ici lui attribuent une valeur non nulle calculée à partir d’un historique réduit.
La fréquence conditionnelle relative fr d’un mot w selon un historique h s’écrit :
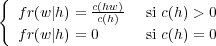 | (1.10) |
Toutes les méthodes de discounting introduisent une fréquence conditionnelle décomptée fr∗(w|h) telle que :
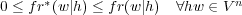 | (1.11) |
Pour un historique h donné, la redistribution de la masse de probabilités ôtée de fr s’effectue à l’aide d’une composante appelée la probabilité de fréquence nulle (zero-frequency probability), calculée à partir de fr∗.
La probabilité de fréquence nulle, notée λ, est définie comme suit :
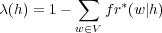 | (1.12) |
Cette définition implique que pour un historique jamais observé (c(h) = 0), alors λ(h) = 1.
Pour un mot w jamais rencontré après l’historique h, la probabilité de fréquence nulle associée à h est utilisée pour pondérer la valeur de P(w|h′), où h′ est un historique moins restrictif que h et pour lequel on suppose que l’événement h′w a plus de chance d’avoir été observé que hw.
Le lissage par repli [Katz, 1987] est un lissage de type hiérarchique. Le principe de cette technique consiste à utiliser un modèle de langage plus général lorsqu’un modèle spécifique ne détient pas suffisamment d’information pour un contexte donné.
Par exemple, lorsque pour un n-gramme hw, où h correspond aux n − 1 mots précédant le mot w, aucune observation n’a été obtenue sur le corpus d’apprentissage, le modèle n-gram se tourne vers un modèle de niveau inférieur (n-1)-gramme : ce processus peut bien sûr être réitéré jusqu’au niveau le plus bas, le zéro-gramme, qui consiste en l’attribution d’une constante indépendante du mot w.
La probabilité d’un n-gram est donc estimée à partir du lissage de l’approximation la plus significative (du point de vue de la quantité d’observations) :
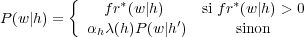 | (1.13) |
avec
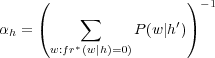
qui permet à la distribution P(w|h) de respecter la contrainte de sommation à 1.
Bien que la formule (1.3) suggère que la probabilité du modèle acoustique et la probabilité du modèle de langage peuvent être combinées à travers une simple multiplication, il est nécessaire en pratique d’effectuer une pondération. Sans cela, la participation d’un des modèles est négligeable à cause de la différence de l’ordre de grandeur de leurs probabilités. En effet, les probabilités du modèle acoustique sont beaucoup plus petites que celles du modèle de langage : P(A|W) « P(W).
La solution la plus couramment utilisée pour atténuer ce problème consiste à ajouter un poids, noté lw (pour linguistic weight) et souvent appelé fudge factor, au modèle de langage. On a alors :
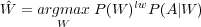 | (1.14) |
Le poids lw est déterminé empiriquement à partir d’expériences effectuées sur un corpus de développement : la valeur choisie est celle qui optimise les performances du système de reconnaissance. Généralement, lw > 1.
La contribution du modèle de langage peut aussi être interprétée comme une pénalité sur le nombre de mots. En fonction des valeurs des probabilités du modèle de langage, le système peut privilégier une séquence composée de peu de mots longs ou, au contraire, une séquence constituée de nombreux mots courts. Afin d’ajuster au mieux la tendance du système à insérer ou supprimer des mots, une valeur appelée pénalité linguistique et notée lp est insérée dans la formule (1.14), qui devient :
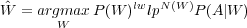 | (1.15) |
où N(W) est le nombre de mots de la séquence W.
Tout comme le fudge factor lw, la pénalité linguistique lp est déterminée empiriquement : la valeur choisie doit optimiser les performances du système de reconnaissance pour des expériences effectuées sur un corpus de développement.
Les multiplications successives de probabilités, c’est-à-dire de valeurs comprises entre 0 et 1, mènent à manipuler des valeurs de plus en plus proches de 0. La limite de capacité de représentation de valeurs proches de 0 d’un ordinateur est rapidement atteinte, à moins de mettre en place des mécanismes coûteux en terme de temps de calcul. En pratique, les systèmes de reconnaissance de la parole ne manipulent pas directement les probabilités : ce sont les logarithmes de ces probabilités qui sont utilisés. Le passage aux logarithmes entraîne l’utilisation d’additions plutôt que de multiplications : ce type d’opérations conforte la propriété intéressante des logarithmes qui changent très lentement d’ordre de grandeur. Ainsi, la formule (1.15) se ré-écrit :
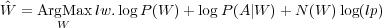 | (1.16) |
À partir de l’observation d’événements acoustiques et de connaissances a priori (lexique, modèles acoustiques, ...), un système de reconnaissance génère un ensemble d’hypothèses de séquences de mots. Cet ensemble est appelé espace de recherche : le système doit en extraire la phrase qui satisfait l’équation (1.15). L’espace de recherche est généralement représenté sous la forme d’un graphe, appelé graphe de recherche, qui intègre les informations utilisées pour la génération des hypothèses : informations temporelles, unités acoustiques (phonèmes, syllabes, demi-syllabes, ...) associées à leurs scores acoustiques (probabilités données par le modèle acoustique), mots induits par les séquences d’unités acoustiques, ...
La recherche de la phrase de probabilité maximale au sein d’un graphe de recherche est analogue au problème de la recherche du chemin de poids minimal dans un graphe. De nombreux algorithmes existent pour résoudre ce problème [Cettolo et al., 1998]. Cependant, pour la majorité des systèmes, la taille de l’espace de recherche est très importante et ralentit considérablement le traitement. Pour obtenir une solution dans un délai acceptable, une recherche en faisceau, appelée beam search, permet de restreindre l’espace de recherche en supprimant des hypothèses qui semblent localement peu probables [Ney et al., 1992]. Cet élagage ne garantit pas l’obtention de la phrase la plus probable, mais le compromis entre la durée du traitement et la perte de précision est très souvent largement acceptable.
L’utilisation de modèles de langage sophistiqués, par exemple un modèle N-grammes avec un N assez grand, ralentit la recherche de la phrase de probabilité maximale. La solution la plus répandue consiste à utiliser ce type de modèle lors d’une deuxième passe : le graphe de recherche généré lors d’une première passe est élagué grâce à l’application d’un algorithme de beam search, et n’est plus composé que de mots. Chaque mot est alors associé à un score acoustique calculé à partir des scores des unités acoustiques qui le composent. Le graphe obtenu pour la deuxième passe est un graphe de mots : il est l’objet de traitements linguistiques lourds qui auraient fortement ralenti le processus de reconnaissance s’ils avaient été appliqués sur l’intégralité de l’espace de recherche dès la première passe.
Généralement, le modèle de langage stochastique utilisé en première passe d’un processus de reconnaissance de la parole est un modèle Bi-grammes, voire Tri-gramme. Ces modèles ont la particularité d’être simples d’emploi et relativement peu coûteux en temps de calcul. Ces caractéristiques, combinées à l’influence largement bénéfique de ces modèles sur les résultats d’un processus de reconnaissance, sont à l’origine de leur très forte implantation dans les systèmes de reconnaissance de la parole. Les modèles de langage plus évolués, faisant appel à des historiques plus importants ou à des sources de connaissances supplémentaires, sont utilisés en seconde passe sur un espace de recherche réduit à un graphe de mots ou à une liste des N-meilleures phrases. Le graphe de mots ou la liste des N-meilleures hypothèses sont issus du décodage effectué en première passe. Cette seconde passe, qui consiste à utiliser un ou plusieurs modèles nécessitant plus de ressources qu’un modèle Bi-grammes afin d’améliorer encore la reconnaissance, est habituellement connue sous le nom de phase de rescoring.
Bien entendu, rien n’empêche d’utiliser ces modèles de langages gourmands en ressources dans un système de reconnaissance basé sur une seule passe. Malheureusement, les algorithmes utilisés et la technologie actuelle ne permettent pas d’obtenir des résultats satisfaisants dans des délais raisonnables. Dans une application conviviale de dialogue entre un homme et une machine, le système de reconnaissance de la parole doit avoir un temps de réponse proche du temps réel. L’utilisation de systèmes multi-passes permet d’utiliser des modèles de langage nécessitant de grosses ressources sans trop ralentir le processus global de reconnaissance.