![′
V2 = V.V = {w |w = v||v, v et v ∈ V }
Vk = {(v ...v ...v )v ∈ V,∀i ∈ [1,k]}
1k−1 i kk−1i k−1
= V.⋃V = V⋃V = V⋃ V
V + = V k = V V2 ... V k...
k>0
V∗ = {𝜖}⋃ V+ = V 0⋃ V + = ⋃ Vk avec par convention V0 = {𝜖}
k≥0](these_v1.030x.png)
|
Sommaire |
Deux points importants sont à retenir des chapitres précédents :
Nous proposons dans les travaux de cette thèse une architecture de décodage conceptuel, i.e. une
méthode permettant de tenir compte de ces concepts dans la génération de la transcription. La détection
des concepts dans une intervention utilisateur se fait généralement par une analyse à base de
grammaire. Nous utiliserons ce formalisme et en particulier le formalisme des grammaires régulières
encodées sous la forme d’automate à états fini pour effectuer cette opération. Le chapitre 3.2
introduit cette notion de modélisation formelle du langage. Le chapitre 3.4 présente les outils
qui seront utilisés pour implémenter cette modélisation, à savoir les automates à états fini.
Plusieurs articles ont montré, [Schapire et Singer, 2000, Haffner et al., 2003, Karahan et al., 2003, Tur et al., 2004], que les outils de classification de texte (les classifieurs à large-marge comme les machines à support vectoriels (SVM) ou les implémentations de l’algorithme de boosting peuvent être un moyen efficace pour détecter des concepts notamment dans les systèmes de routage d’appel, par exemple [Gorin et al., 1997]. Les arbres de décisions sémantiques (SCT-Semantic Classification Tree) décrits dans [Kuhn et De Mori, 1995] ont également été utilisés dans des systèmes de dialogue similaires à ceux présentés dans ces travaux (application ATIS). Cette approche de détection de concepts a 2 principaux avantages :
Nous proposons d’effectuer la détection de concepts au travers de ces méthodes. Le chapitre 3.5 introduit alors les notions de classification que nous utiliserons.
Bien que les applications de reconnaissance de la parole fonctionnent généralement au moyen de modèles de langage statistiques, plusieurs travaux présentent de nouvelles voies intermédiaires dans le but de combiner l’approche formelle et l’approche statistique afin de tirer parti du meilleur de ces 2 approches. [Estève, 2002] propose par exemple des modèles de langages hybrides s’appuyant sur l’intégration de connaissances linguistiques a priori (grammaires locales) dans un modèle statistique. Cette section présente l’approche formelle de modélisation du langage.
Soit un alphabet V , un ensemble fini de symboles ou de caractères, une chaîne w = (v1,v2,…,vn) un n-uplet d’éléments appartenant à V , l’opération de base sur les chaînes, la concaténation :
Sur V ∗ la concaténation notée || est une opération
 |
Un langage formel L construit à l’aide d’un vocabulaire V est un sous-ensemble du monoïde libre V ∗. Un langage L sur V ∗ : L ⊆ V ∗.
L’ensemble des langages réguliers sur un vocabulaire V peut-être défini récursivement par les règles suivantes :
Notons que certains langages ne sont pas réguliers, comme par exemple le langage {an.bn|n > 0} défini sur le vocabulaire {a,b}.
Les expressions régulières fournissent une autre méthode de description des langages réguliers. Les expressions régulières (E.R.) sur un alphabet V et les langages qu’elles décrivent sont définis récursivement de la manière suivante :
Remarques : pour économiser des parenthèses, par convention, on établit les priorités décroissantes suivantes : ∗, concaténation, |.
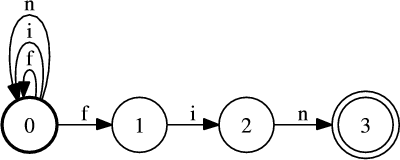
Exemple : considérons le vocabulaire suivant V fin = {f,i,n}, le langage Lfin = {(f|i|n)∗fin} = {fin,ffin,niffin,iiiifin,…} sur V fin∗ est un langage régulier où toutes les chaînes appartenant au langage sont composées de n’importe quelle chaîne composée des symboles du vocabulaire {f,i,n}, mais se terminant par la chaîne « fin ».
Si un langage est fini, on peut le définir en listant l’ensemble des chaînes le composant : définition en extension. Si le langage est infini, la définition extensive est impossible, il est nécessaire d’avoir recours à une définition en compréhension. Le but est de trouver un moyen de spécifier un langage. Une grammaire formelle permet avec un nombre fini de règles de générer un langage donné.
[Chomsky, 1957, Chomsky, 1965] définit une grammaire G comme un quadruplet G = (V T,V N,R,A), avec :
Chomsky a effectué une classification des grammaires formelles (appelée « hiérarchie de Chomsky ») en différents types selon leur capacité descriptive, c’est à dire selon la complexité des langages qu’elles engendrent. Les grammaires sont habituellement divisées en 4 types selon les contraintes posées sur les règles de productions :
La relation entre ces 4 types de grammaire est bien sûr la suivante :
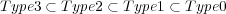
Les grammaires hors contexte sont les plus utilisées pour le traitement du langage naturel, bien qu’il ait été prouvé que celui-ci n’est pas engendré par une grammaire de ce type [Pullum et Gazdar, 1982]. Cette utilisation répandue vient du bon compromis existant entre la capacité de description des grammaires hors-contexte et les restrictions qu’elles induisent au niveau de l’analyse grammaticale : ces restrictions permettent une analyse efficace, et la puissance de description des grammaires hors-contexte permet de décrire une grande partie de la structure d’un langage. Pour des applications restreintes concernant le traitement du langage naturel, les grammaires régulières sont préférées aux grammaires hors-contexte : puisque la partie visée du langage est déterminée, la capacité de description des grammaires régulières s’avère suffisante. Notamment dans le contexte de dialogue où nous avons à faire à des phrases courtes, il est aisément possible d’obtenir une grammaire régulière à partir d’une hors-contexte. De plus, leur analyse grammaticale est plus efficace, en terme de rapidité, que celle des grammaires hors-contexte.
Dans la pratique, les langages réguliers ne sont donc pas utilisables pour décrire des phénomènes trop complexes, mais ils se prêtent facilement à la modélisation de phénomènes de portée réduite et localisée. Tout langage régulier peut être engendré par une grammaire régulière. Un exemple de grammaire régulière engendrant le langage de l’exemple 3.2.4 est la suivante :
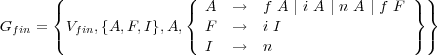 |
À chacune des grammaires présentées, peut être associé un type d’automate qui accepte le langage engendré par cette grammaire. Ces automates sont des machines virtuelles qui permettent de signifier l’appartenance ou non d’une phrase à un langage. Le tableau 3.1 établit la correspondance entre les quatre grands types de grammaires présentées précédemment et quatre sortes d’automates.
|
Les grammaires utilisées dans le traitement effectué par les systèmes de dialogue sont généralement des grammaires régulières et hors-contexte. Dans un contexte de dialogue oral où les phrases sont finies et de taille limitée, il est possible d’obtenir une approximation d’une grammaire hors-contexte par une grammaire régulière [Mohri et Nederhof, 2001]. Les automates à états fini sont alors appropriés pour représenter les connaissances linguistiques dans les systèmes de dialogue et sont présentés dans la section suivante.
Les automates sont des machines qui prennent en entrée une chaîne de symboles et qui effectuent un
algorithme de reconnaissance de la chaîne. La chaîne est reconnue par l’automate si et seulement si
celui-ci part d’un état initial, lit tous les symboles de la chaîne, puis s’arrête dans un état final. Le
langage accepté par un automate à états fini est l’ensemble des chaînes dont les symboles font passer de
l’état initial de l’automate jusqu’à un de ses états terminaux par une succession de transition utilisant
tous ces symboles dans l’ordre.
Plus formellement, un automate à états fini est un quintuplet A = (Q,V,δ,s,F) où :
δ est la fonction de transition de l’automate. δ(e,a) = e′ indique que si l’automate est dans l’état e et
qu’il rencontre le symbole a, il passe dans l’état e′. De plus, pour tout e de Q, δ(e,𝜖) = e.
Un automate à états fini possède les propriétés suivantes :
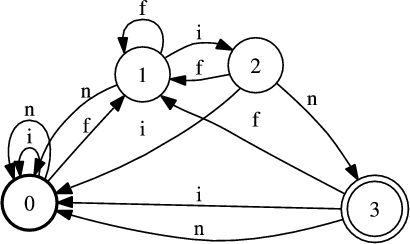
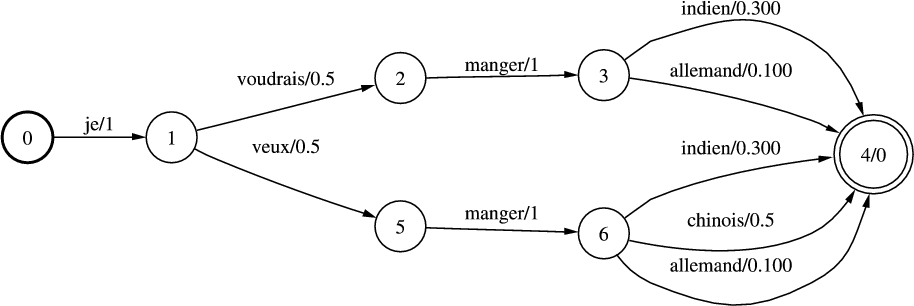
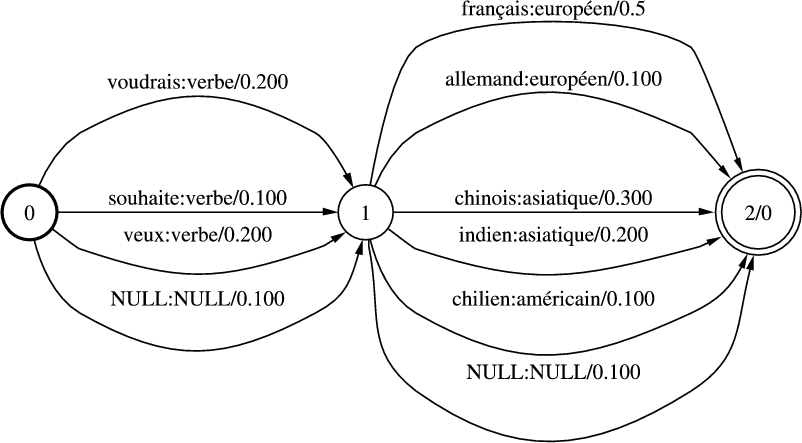
Un automate associé à l’expression régulière 3.2.4 est visible dans la figure 3.1. Cet automate à état fini est non-déterministe. C’est à dire qu’il existe au moins un couple, formé d’un état et d’un symbole, qui admette plus d’une image par la fonction de transition (δ(1,f) = 1 et δ(1,f) = 2 dans l’exemple de la figure 3.1). Dans ce cas l’automate doit faire des choix pour progresser. Un automate non-déterministe reconnaît une phrase si parmi tous les choix possibles pour l’analyser, il en existe au moins un qui le laisse dans un état final. L’inconvénient d’un automate non-déterministe est d’analyser les chaînes plus lentement que les automates déterministes. En effet, si un mauvais choix est pris dans une transition, il faut revenir en arrière jusqu’à ce choix pour parvenir à la reconnaissance de la chaîne. Par exemple la chaîne « ffin », à la lecture du premier symbole deux possibilités sont offertes, passage à l’état 1, ou rester en l’état 0. Si l’on passe à l’état 1, nous sommes dans un état ou il est alors impossible d’effectuer de transition, or la chaîne n’est pas encore entièrement lue, dans ce cas il faut donc revenir à l’état 0 et choisir de rester. La complexité de la reconnaissance d’une chaîne par un automate non-déterministe est dite exponentielle. Si, à chaque état et pour chaque symbole, existent n transitions possibles, la reconnaissance d’une chaîne de longueur p demandera jusqu’a np transitions. Un algorithme permet de déterminiser tout automate à états fini, c’est à dire de faire en sorte que sa fonction de transition n’admette pour tout état et tout symbole, qu’au plus un état dans lequel l’automate peut transiter. La version déterministe de l’automate de la figure 3.1 est visible dans la figure 3.2.
|
|
|
|
Toutes les opérations présentées sur les FSMs sont faites avec la suite d’outils d’AT&T ([Mohri et al., 1997]). Suivant les définitions utilisées dans [Mohri et al., 2002], les accepteurs et transducteurs utilisés dans cette étude sont définis en accord avec la notion générale algébrique du semi-anneau (semiring). Un semi-anneau K est un ensemble 𝕂 avec une opération associative et commutative ⊕, une opération associative ⊗, ainsi que deux éléments neutres 0 et 1 : K = (𝕂,⊕,⊗,0,1). Les poids associés aux hypothèses générées par le module de reconnaissance automatique de la parole (RAP) représentent les probabilités codées en −log. Le semi-anneau correspondant est appelé le log semiring : (ℝ,+,.,0,1). Lorsque sont utilisées les probabilités en −log pour une approximation du meilleur chemin, un semi-anneau tropical (tropical semiring) est utilisé : (ℝ+ ∪∞,min,+,∞,0).
|
Les accepteurs et transducteurs sont définis comme suit :
Soient Σ un alphabet de symboles d’entrées ; Δ un alphabet de symboles de sorties ; 𝜖 un symbole vide ; Q un ensemble d’états (avec I=état initial et F=états terminaux) ; 𝕂 un semi-anneau ; E un ensemble de transitions défini comme : E ⊆ Q × (Σ ∪{𝜖}) × (Δ ∪{𝜖}) × 𝕂 × Q ; w une fonction de pondération : w : Q → 𝕂.
Si Path(R1,x,R2) est un ensemble de chemins de R1 ⊆ Q à R2 ⊆ Q avec un symbole d’entrée x et Path(R1,x,y,R2) un ensemble de chemins dans Path(R1,x,R2) avec un symbole de sortie y, alors :
 = ⊕ w [π]
π∈Path(I,x,F)](these_v1.036x.png) | (3.1) |
 = w[π]
π∈Path(I,x,y,F)](these_v1.037x.png) | (3.2) |
et w[π] = w[t1] ⊗ w[t2] ⊗… ⊗ w[tn] pour un chemin π fait des transitions suivantes t1,t2,…,tn.
Différentes opérations fondamentales sur les FSMs utilisées dans ce document sont présentées :
Soit l’automate A1 acceptant un langage L1 ⊆ V ∗ (exemple figure 3.3) et un automate A2 acceptant un langage L2 ⊆ V ∗ (exemple figure 3.4), l’automate A1∪2 (exemple figure 3.5) résultant de l’union des deux automates A1 et A2 au moyen de l’opération :
 = [A1 ](x)∪ [A2 ](x)](these_v1.038x.png)
Soit l’automate A1 acceptant un langage L1 ⊆ V ∗ (exemple figure 3.3) et un automate A2 acceptant un langage L2 ⊆ V ∗ (exemple figure 3.4), l’automate A1∩2 (exemple figure 3.7) résultant de l’intersection des deux automates A1 et A2 au moyen de l’opération suivante :
 = [A1 ](x)⊗ [A2](x)](these_v1.043x.png)
Soit l’automate A1 acceptant un langage L1 ⊆ V ∗ (exemple figure 3.3) et un automate A2 acceptant un langage L2 ⊆ V ∗ (exemple figure 3.4), l’automate A1∩2 (exemple figure 3.8) résultant de la différence des deux automates A1 et A2 au moyen de l’opération suivante :
 = [A1 ∩ A2](x)](these_v1.045x.png)
L’opération de projection à partir d’un transducteur permet d’obtenir un accepteur de même topologie, avec les transitions étiquetées comme les entrées du transducteur si cette projection se fait sur les entrées, où comme les sorties si cette projection se fait sur les sorties :
 = [T](x,y) et [A ](y) = [T](x,y)
y x](these_v1.047x.png)
La composition est une opération entre deux transducteurs. Elle permet d’aligner les symboles de sortie du premier transducteur (exemple figure 3.9) avec les symboles d’entrée du second (exemple figure 3.10) et de produire un transducteur dont les entrées sont celles du premier transducteur et les sorties celles du second (exemple figure 3.11).
[T1 ∘ T2](x,y) = ⊕ z[T1](x,z) ⊗ [T2](z,y)
|
|
L’application des arbres de décisions sémantiques au langage naturel a été introduite dans [Kuhn et
De Mori, 1995]. La nouveauté des algorithmes de SCT réside dans la construction des questions pour
l’apprentissage de l’arbre de décision. Cette construction se fait à partir d’un ensemble d’expressions
régulières Π0 associé à la racine de l’arbre :
soient V , l’ensemble des mots du vocabulaire du corpus d’entraînement C0, w ∈ V n’importe quel mot du
vocabulaire, le symbole « + » indiquant la présence de n’importe quelle séquence de mots non vide dans
l’expression régulière, Π0 contient les quatre éléments suivants :
Π0 = {w,+w,w+,+w+}
L’ensemble des questions appliquées à la racine, N0, est obtenu en considérant toutes les expressions régulières Π0 possibles appliquées sur tous les w du vocabulaire V selon les quatre éléments de Π0. Il y a donc 4 ×|V | possibilités où |V | représente la taille du vocabulaire. Chaque expression régulière est alors testée à la racine de l’arbre. Le critère d’impureté de Gini est utilisé pour choisir la meilleure question à chaque nœud Ni. Soient les k classes c1,c2,...,ck dont les probabilités de répartition sont p1,p2,...,pk alors le critère de Gini du nœud Ni s’exprime par :
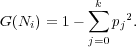 |
La meilleure question pour Ni est celle qui apporte la plus grande variation d’impureté entre Ni et ses fils. Si les deux enfants de Ni sont notés Ni+1oui et Ni+1non, la variation d’impureté Δi est alors définie par :
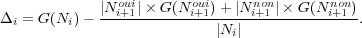 |
Par exemple, si +W est l’expression régulière qui maximise Δi, la phrase qui est acceptée par cette expression régulière fait partie d’un corpus C1oui associé au fils de la branche du corpus nommé OUI. Les autres font partie du corpus C1non associées au fils nommé NON. L’ensemble des questions associé à C1oui est obtenu par la substitution suivante : + → Π0 nous menant à Π0W. En général, étant donnée une expression régulière : +W1 + W2 + … + Wi + … où Wi est déjà déterminé par une série de mots, les questions sont générées en remplaçant chaque + par Π0, c’est à dire :
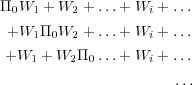
Soit | + | le nombre de symboles + dans l’expression régulière originale, le nombre de cas est alors : 4 ×| + |×|V |.
Lorsque le SCT est construit, il prend des décisions sur la base de règles de classification statistique apprises sur ces expressions régulières. Les règles apprises par le SCT sont donc résistantes aux diverses formulations du locuteur car elles ne dépendent que d’un petit nombre de mots. En revanche, si un seul des mots composants de la règle est mal reconnu, elle ne s’applique pas.
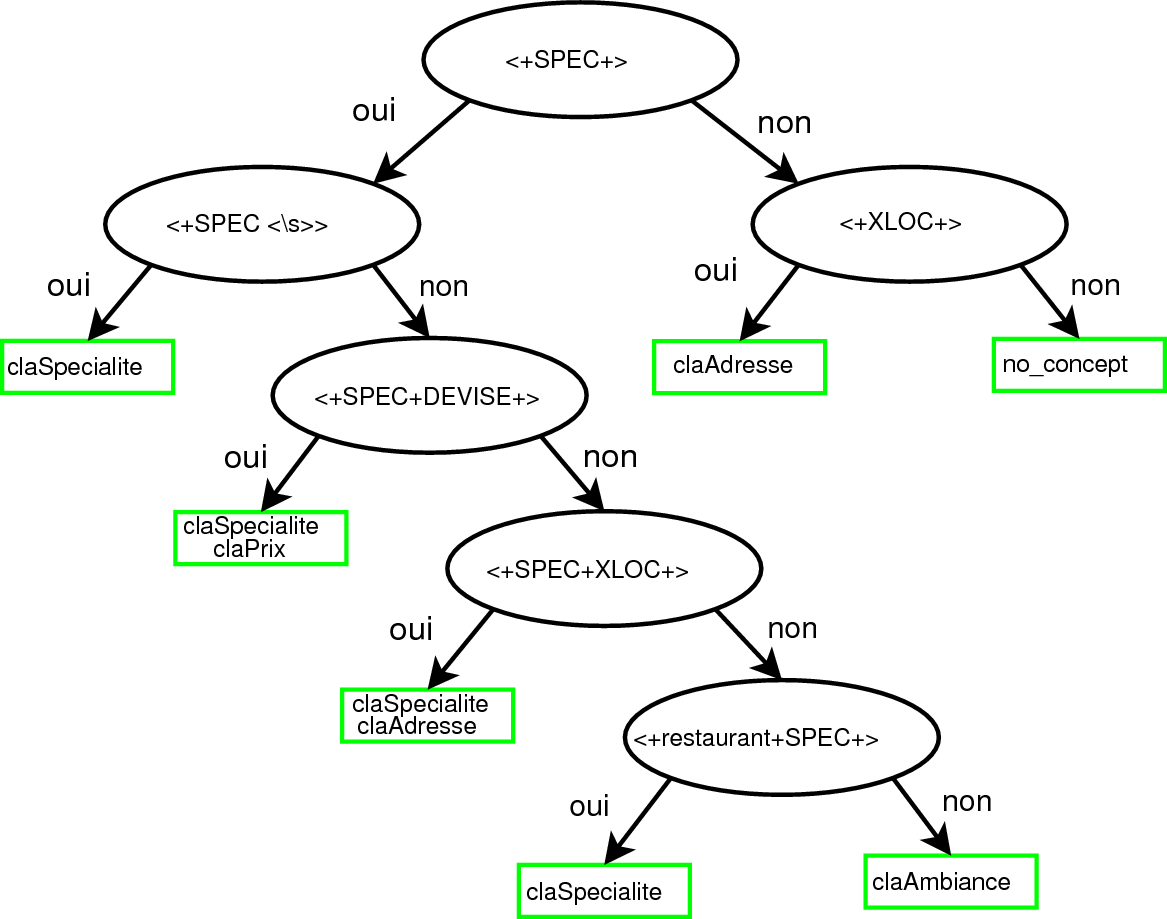
La figure 3.12 est un exemple d’arbre.
Le Boosting est une méthode générale pour améliorer les performances de n’importe quel algorithme d’apprentissage. Par définition, un algorithme de Boosting peut théoriquement transformer un algorithme d’apprentissage basique (appelé « weak learner ») avec des performances juste un peu meilleures que le hasard en un algorithme très performant. Le principe de ces algorithmes de Boosting est re-pondérer à plusieurs reprises les exemples d’apprentissage et de refaire tourner l’algorithme d’apprentissage sur ces exemples re-pondérés. Les exemples mal classés sont re-pondérés à la hausse tandis que les biens classés sont re-pondérés à la baisse. Ainsi, le boosting force cet algorithme à concentrer ses efforts d’apprentissage sur les exemples les plus difficiles. L’hypothèse finale est un vote pondéré des différentes hypothèses obtenues à chaque instance de l’algorithme d’apprentissage. L’algorithme AdaBoost [Freund et Schapire, 1996] est présenté dans la figure 3.13.
Les SVMs, proposés par Vapnik ([Vapnik, 1982, Vapnik, 1995]), sont une classe d’algorithmes
d’apprentissage qui ont été utilisés avec succès dans plusieurs tâches d’apprentissage. Ils permettent de
construire un classifieur à valeurs réelles qui découpent le problème de classification en 2
sous-problèmes : transformation non-linéaire des entrées et choix d’une séparation linéaire
optimale. Ils offrent en particulier une bonne approximation du principe de minimisation du
risque structurel. L’idée de la minimisation du risque structurel est de trouver une hypothèse
h pour laquelle l’erreur vraie minimale est garantie. L’erreur vraie de h est la probabilité
que h fasse une erreur sur un exemple non-vu et extrait aléatoirement du corpus de test.
Le premier sous-problème à traiter est donc celui de travailler dans un espace où les données soient
linéairement séparables. Les données sont alors projetées dans un espace de grande dimension par une
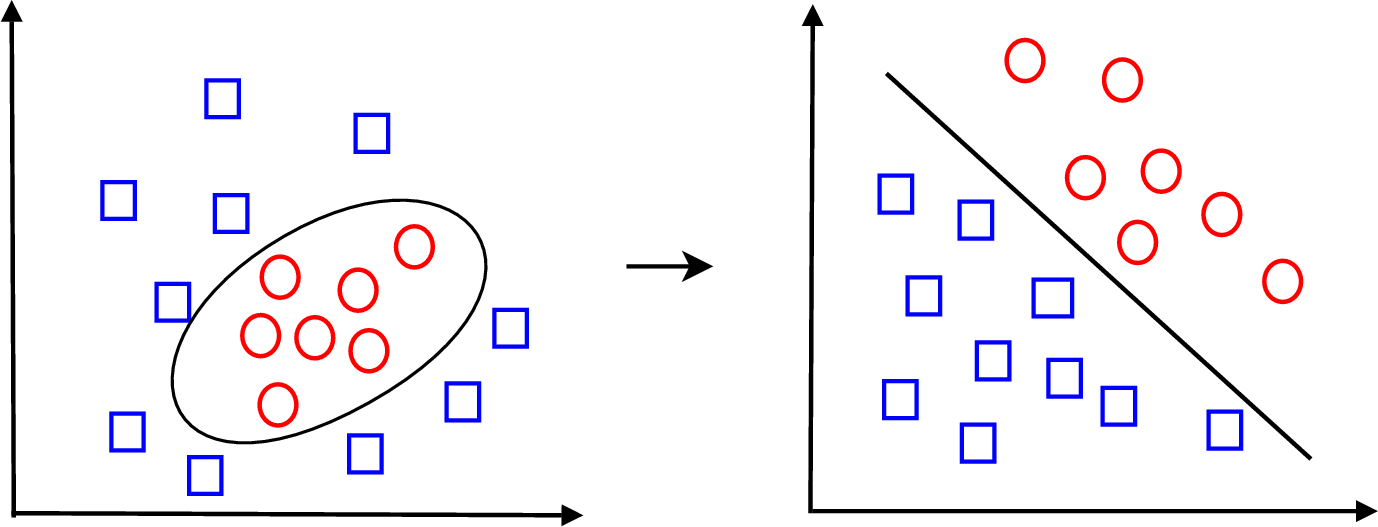
transformation basée sur un noyau (voir figure 3.14). Le noyau est une fonction qui retourne la valeur du
produit scalaire des images des 2 arguments K(x1,x2) = 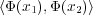 . Il peut être linéaire, polynomial
ou gaussien .
. Il peut être linéaire, polynomial
ou gaussien .
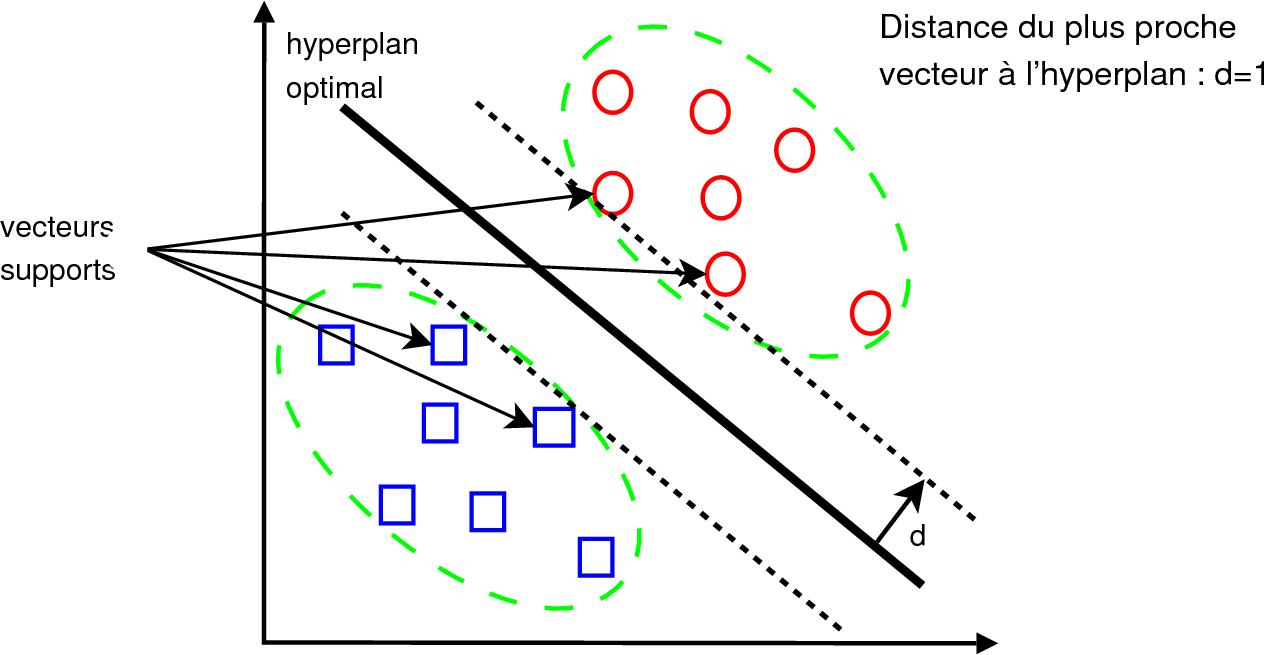
Le deuxième sous-problème est traité dans cet espace transformé. Les classes y sont séparées par des classifieurs linéaires qui déterminent un hyper-plan optimal. L’hyper-plan optimal est celui qui sépare correctement toutes les données et qui maximise la marge, la distance du point le plus proche à l’hyper-plan (représentée par d dans la figure 3.15). Les hyperplans peuvent être déterminés au moyen d’un nombre de points limité qui seront appelés les « vecteurs supports ».
Pour appliquer les SVMs sur du texte, la technique la plus simple employée est celle du sac de mots
où tous les mots sont représentés par des chiffres. Le lexique complet représente alors un vecteur et
chaque phrase sera codée par ce vecteur.
L’utilisation des SVMs dans ce cas est alors pleinement justifiée [Joachims, 1998].





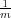 pour tout
pour tout 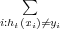
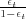 .
.
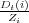
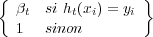
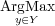
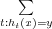
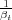 .
.