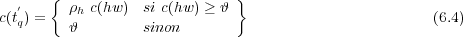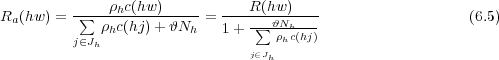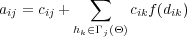
|
Sommaire |
Dans les applications de dialogue homme-machine, l’interprétation sémantique de la phrase exprimée par un utilisateur est effectuée sur la transcription générée par le moteur de reconnaissance de la parole. Cette reconnaissance est entachée d’erreurs, et la qualité de l’interprétation sémantique de la phrase est bien sûr très dépendante de la qualité de la reconnaissance. Une mauvaise interprétation peut amener le gestionnaire de dialogue à faire de mauvais choix et donc mécontenter l’utilisateur. Le développement de mesures de confiance sur la transcription est alors crucial. Ces mesures de confiance sont utiles pour réaliser 2 objectifs :
Typiquement, les mesures de confiance dépendent du type de tâche et de l’application. Les mesures populaires (voir par exemple [Falavigna et al., 2002]) sont les scores donnés par le modèle acoustique et de langage, la densité du treillis, le comportement de repli du modèle de langage et les probabilités a posteriori. Dans la plupart, si ce n’est toutes les études, le moyen d’incorporer les informations sémantiques dans le processus de décision est plutôt ad-hoc. Une approche systématique est proposée dans [Sarikaya et al., 2005].
Les mesures de confiance peuvent opérer à différents niveaux : mot, concept ou phrase. Elles peuvent exploiter différentes sources de connaissance : acoustique, linguistique ou sémantique. Les mesures linguistiques sont plus adaptées à estimer la qualité d’une phrase, tandis que les mesures acoustiques sont plus destinées a être utilisées au niveau du mot. Nous proposons dans ce chapitre un ensemble de mesures de confiance faisant intervenir différentes sources de connaissances permettant d’estimer la qualité de la reconnaissance à plusieurs niveaux : mot, concept et phrase. Ces mesures de confiance ne sont pas destinées à être comparées mais à nous donner un ensemble d’outils de diagnostics qui sera utilisé pour établir une stratégie d’aide à la décision présentée dans le chapitre 7.
Nous présenterons dans un premier temps, des mesures linguistiques intervenant au niveau de la phrase. L’observation qui a servi de point de départ à ces mesures est qu’une des raisons des taux d’erreurs mot élevés dans la transcription est que les modèles de langage N-grammes utilisés sont appris avec peu de données. Il en résulte que les probabilités des événements linguistiques sont peu fiables et que les méthodes de repli utilisées pour calculer la probabilité des événements non-observés sont parfois source d’erreurs de reconnaissance. Nous avions travaillé sur l’élaboration de techniques d’augmentation de données pour des modèles de langage N-grammes afin d’avoir recours aux méthodes de repli le moins souvent possible. Nous proposons une première mesure linguistique basée sur des situations de confiance obtenues par le consensus de différents décodages utilisant ces modèles, en parallèle avec un modèle classique (section 6.2). En suivant la même idée, (section 6.3), nous présenterons d’autres mesures de confiance mesurant la fréquence de l’utilisation des méthodes de repli.
Nous présentons ensuite une mesure acoustique classique permettant d’estimer la qualité de reconnaissance d’un mot, cette mesure est étendue au niveau conceptuel.
Nous présentons dans la dernière partie (section 6.5) une mesure de confiance sémantique adaptée pour estimer une confiance au niveau conceptuel. Cette méthode est basée sur l’utilisation redondante de classifieur.
Si les données d’apprentissage d’un modèle de langage sont limitées, de nombreux Bi-grammes et surtout Tri-grammes qui apparaîtraient plus d’une fois dans un corpus idéalement dimensionné ont une probabilité estimée par un modèle de repli. Cette probabilité est souvent très différente de celle qui aurait été calculée avec un corpus d’apprentissage plus riche. De plus, dans beaucoup d’applications le corpus d’apprentissage disponible est biaisé par le fait qu’il a été collecté avec un nombre restreint de locuteurs et dans une période de temps limitée. L’effet produit est que la probabilité de certains Bi-grammes ou Tri-grammes est anormalement élevée. Ces considérations suggèrent que les comptes de certains événements plausibles devraient être générés même s’ils ne sont pas observés dans le corpus d’apprentissage. Nous présentons respectivement dans les sections 6.2.2 et 6.2.3, 2 méthodes permettant d’inférer de nouveaux événements et donc de limiter l’utilisation du back-off.
La représentation des mots par des vecteurs dans un espace réduit peut être obtenue [Bellegarda, 1998], [Berry, 1992], [Searle, 1982] par décomposition en valeurs singulières (SVD)
Soit cij le nombre de fois où le mot wi a été réellement observé dans le corpus d’apprentissage avec l’historique hj. Soit aij le compte pour le même mot et historique obtenu par augmentation de données. Prenons djk la distance entre les vecteurs représentant les historiques hj and hk dans l’espace réduit. Notons Γj(Θ) l’ensemble des historiques dont les vecteurs sont proches du vecteur représentant hj dans l’espace réduit. Le compte augmenté aij de la séquence [(hj = wj)wi] est obtenu, supposant que l’historique hk contribue aux comptes de la séquence [(hj = wj)wi], en fonction du degré de similarité entre les deux historiques hj et hk :
|
| (6.1) |
Ce degré de similarité est représenté par une fonction f(dik) de la distance entre la représentation des deux historiques. La fonction f(dik) doit être égale à 1 quand dik = 0 et doit diminuer avec dik. Une fonction acceptable peut être celle de l’équation 6.2.
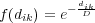 | (6.2) |
où D est un paramètre pour régler le système. Dans le modèle utilisé dans les évaluations, D a été fixé à 1. La distance ([Janiszek et al., 2000]) Euclidienne entre chaque paire de vecteurs d’historique est calculée dans l’espace réduit. Il est intéressant de noter que le calcul de ces distances peut être obtenu sur un corpus différent de celui de l’application visée. Le modèle Ba utilisé dans la section 6.2.5 a été créé à partir des distances calculées sur un corpus généraliste composé d’articles du journal "Le Monde" de 40 millions de mots. Les distances peuvent être obtenues ou modifiées en utilisant d’autres critères comme la synonymie.
Cette augmentation de données accroît le nombre de Bi-grammes avec un compte supérieur à zéro. Néanmoins, un compte augmenté reste égal à zéro quand son compte avant augmentation était nul et qu’aucun historique proche du sien n’a été trouvé. Dans ce cas, les Bi-grammes peuvent être augmentés par d’autres techniques. En pratique, l’ensemble Γj(Θ) est construit en considérant uniquement les distances inférieures à un seuil.
Prenons tg = xwcwd, tc = wgxwd, td = wgwcx, 3 Tri-grammes dans lequel le mot x apparaît. Considérons c(tq) étant le compte du Tri-gramme tq(q=g,c,d). Nous souhaitons dériver par analogie le compte pour les Tri-grammes tg′ = ywcwd, tc′ = wgywd, td′ = wgwcy si x et y satisfont le prédicat Analogue(x,y) défini dans la formule 6.3 :
![Analogue(x,y) = [POS (x) = POS (y)]∧[SemComp (x,y)]](these_v1.0113x.png) | (6.3) |
où POS(w) indique la classe syntaxique (POS) du mot w. SemComp(x,y) indique que x et y sont des mots sémantiquement compatibles. La compatibilité sémantique a été définie comme suit :
![[SemComp (x,y) vraie ⇔ d(x,y) < δ]](these_v1.0114x.png)
où d(x,y) est la distance entre les mots x et y définie dans [Janiszek et al., 2000]. δ est un seuil fixé empiriquement.
La possibilité d’acquérir de nouvelles connaissances par analogie a été proposée dans [Evans, 1968, Polya, 1954, Brown, 1977, Yvon, 1996]. Le compte c(tq′) peut être obtenu de plusieurs manières.
Une solution simple consiste à positionner le compte à 𝜗 quand le compte original est inférieur à ce seuil ou que le Tri-gramme généré n’avait pas été observé, comme décrit dans la suite avec t = hw :
Soit Jqh l’ensemble des Tri-grammes dont le compte a été augmenté à 𝜗. Il inclut ceux dont le compte initial n’était pas nul et inférieur à 𝜗q. La constante ρh est dépendante de l’historique et peut être sélectionnée dans le but que la fréquence Ra(hw) des comptes augmentés des Tri-grammes ayant un compte supérieur à 𝜗 avant augmentation soit proche de la fréquence R(hw) que ces comptes avaient avant l’augmentation.
Jh est l’ensemble des Tri-grammes dont le compte avant augmentation était supérieur à 𝜗, Ra(hw) est la fréquence des comptes augmentés et Nh est le nombre de Tri-grammes dans Jqh. Dans le but d’être le plus proche de la condition désirée Ra(hw) ≈ R(hw) pour les Tri-grammes dans Jh, l’inégalité suivante doit être observée :
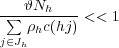
ce qui amène à :
Le compte des nouveaux Tri-grammes ou des Tri-grammes dont le compte est inférieur à 𝜗 peut également être positionné ou réévalué en fonction du compte des Tri-grammes existants à partir desquels ils ont été générés (équation 6.7).
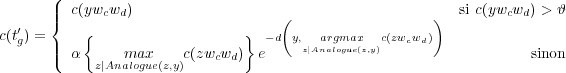 | (6.7) |
Où d est la mesure de distance proposée dans [Janiszek et al., 2000] et α un paramètre choisi empiriquement pour régler le système.
On pourrait croire que l’augmentation des comptes des Tri-grammes selon ce principe revient à utiliser des classes de mots, comme pour les modèles N-classes. Mais ce n’est pas le cas, puisque les comptes modifiés des mots y analogues à x ne sont pas toujours les mêmes et dépendent du contexte. De plus, les probabilités obtenues sont différentes de celles obtenues avec des modèles à base de classes existants. Elles varient selon la distribution initiale des comptes des Tri-grammes et la distance entre les mots.
L’augmentation de données a été expérimentée pour construire des modèles de langage dans le but de générer automatiquement à partir du corpus d’apprentissage complet des événements manquants sur le corpus de test. Deux modèles de langage augmentés ont été créés à partir du corpus d’apprentissage de l’application AGS :
et ont été comparés à l’utilisation d’un modèle général Tri-grammes classique (Tg). Les expériences suivantes ont été menées sur les 1422 graphes du corpus AGS (voir section 4.1). Malgré différents tests, le modèle général reste le plus performant globalement avec un WER de 23% en moyenne sur les 1422 phrases de test, les deux autres modèles ne permettent pas d’améliorer globalement le WER sur ces 1422 phrases, avec un WER de 24% avec l’utilisation de Ta et 25% avec Ba. Toutefois, grâce à leur spécificité ils permettent ponctuellement de meilleures performances que le modèle général sur certaines instances, et notamment des phrases possédant des événements dont la probabilité est calculée par back-off dans l’utilisation de Tg. Si globalement les modèles de langages augmentés ne permettent pas d’améliorer le décodage, leur différence de comportement est exploitée dans la section suivante pour isoler des situations de confiance en fonction des résultats donnés par un décodage en parallèle effectué avec ces 3 modèles.
Des expériences ont également été menées avec des modèles Bi-grammes construits suivant la méthode présentée dans la section 6.2.2 à partir de corpus de tailles différentes et comparées avec un modèle Bi-grammes classique construit à partir du même corpus. L’augmentation de données permet dans un premier temps un meilleur décodage que le modèle classique associé, mais il montre vite ses limites lors de l’utilisation d’un corpus de taille plus élevée.
Appelons H(LM) la meilleure hypothèse de transcription obtenue en utilisant le modèle de langage LM. La comparaison des trois hypothèses obtenues lors de trois décodages en parallèle avec les modèles de langage Tg, Ta et Ba, nous permet d’isoler 3 situations de confiance différentes :
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Le tableau 6.1 montre l’efficacité de la méthode à travers la situation de confiance (la situation no1) qui regroupe 69% des hypothèses pour un WER presque deux fois plus faible que la moyenne sur la totalité des 1422 hypothèses. Il est intéressant de noter que dans la situation no2, même si le modèle Tg donne des résultats globaux meilleurs que les modèles Ta et Ba, sur certaines hypothèses, ces derniers modèles assurent un meilleur décodage. En choisissant la meilleure hypothèse parmi les trois hypothèses produites en utilisant les trois modèles Tg, Ta et Ba, le WER dans la situation no2 passe de 32.83% à 26.65%. 90 hypothèses sur 321 sont concernées (49% à 26%), et 31 sont totalement correctes. Cette stratégie ouvre donc la voie à l’application de stratégie de corrections d’erreurs.
On peut noter également, qu’en augmentant B de l’équation 6.6 pour la génération de Ta, le nombre de phrases dans la situation 1 diminue ainsi que le WER. La situation 1 est donnée pour B = 5, par exemple, avec B = 1000, la situation 1 contient 898 phrases avec un WER de 10.73%.
Peu de mesures de confiance purement linguistiques sont utilisées. [Eide et al., 1995] et [Rayner et al., 1994] en proposent certaines, mais pour être utilisées conjointement avec d’autres méthodes. Nous sommes partis dans une approche de ce type en raison de la constatation suivante : de nombreuses erreurs de reconnaissance sont dues à l’estimation incorrecte des probabilités des événements non observés dans le corpus d’apprentissage. Il est donc intéressant de vérifier si dans les hypothèses apparaissent de tels événements [Uhrik et Ward, 1997], et dans quelle proportion. Nous proposons dans la formule 6.8, une mesure appelée CONS(LM), pour évaluer la consistance d’une hypothèse Hi par rapport au modèle de langage Tri-grammes LM utilisé, i représentant la iieme phrase du corpus de test.
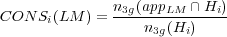 | (6.8) |
où n3g(appLM ∩Hi) est le nombre de Tri-grammes de l’hypothèse Hi qui ont été observés au moins une fois dans le corpus d’apprentissage du modèle LM, et n3g(Hi) est le nombre de Tri-grammes que contient l’hypothèse Hi. Cette mesure de consistance est comprise entre 0 et 1 : 1 correspond à la mesure de consistance optimale. Cette mesure, simple à calculer, donne des résultats très intéressants pour la détection des hypothèses de reconnaissance erronées. Les résultats sur les hypothèses issues de l’utilisation du modèle général Tri-grammes Tg sont visibles dans le tableau 6.2. Ces résultats montrent que la mesure de consistance CONS(LM) est très intéressante pour prédire le taux d’erreurs sur les mots des hypothèses de reconnaissance. Le second intérêt de cette mesure de consistance réside donc dans le type d’erreurs que cette mesure permet de détecter : il s’agit principalement d’erreurs dues au manque de données d’apprentissage caractérisées par la présence de Tri-grammes non vus dans l’hypothèse de reconnaissance 2 , ou bien de graphes de mots ne proposant pas d’hypothèses de vraisemblance acoustique élevée contenant des Tri-grammes observés dans le corpus d’apprentissage.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Le même critère peut être appliqué au niveau d’étiquettes morpho-syntaxiques (POS). Les hypothèses reconnues sont préalablement étiquetées de façon automatique, comme illustré dans le tableau 6.3 :
| ||||||||||||||||||||||||||||||||||||
Le corpus d’apprentissage est étiqueté de la même manière, et la mesure de consistance appelée CONSPOS(LM) est définie comme CONS(LM) explicité dans l’équation 6.8. Cette mesure permet de généraliser la détection de Tri-grammes incorrects au niveau grammatical. Un corpus, une fois transposé dans sa version grammaticale, même de taille limitée assure une couverture supérieure des événements, par rapport à sa version lexicale. Pour cette raison, le procédé permet d’être moins sévère, les hypothèses acceptées suivant cette méthode sont plus nombreuses, mais celles rejetées ont une grande chance d’être incorrectes. Les résultats sont présentés dans le tableau 6.4.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
L’hypothèse de reconnaissance est parfois composée de Tri-grammes incohérents. Ceci est dû à un repli
trop favorable : il arrive ainsi que des Tri-grammes non vus dans le corpus d’apprentissage soient favorisés
au détriment de Tri-grammes observés dans une très faible mesure dans le corpus d’apprentissage. Ce
phénomène est dû, comme énoncé par avant, à des techniques de repli peu fiables. Les critères de
CONS(LM) et notamment de CONSPOS(LM) permettent d’identifier ces Tri-grammes
peu plausibles. En effet, en faisant l’hypothèse que l’ensemble des Tri-grammes d’étiquette
grammaticale observé sur un corpus d’apprentissage de très grande taille est très proche de
l’ensemble des Tri-grammes d’étiquette grammaticale acceptable dans ce langage, il est alors
possible de considérer que tout Tri-gramme d’étiquette grammaticale n’apparaissant pas dans
cet ensemble est peu plausible [Langlois et al., 2003]. Cette hypothèse semble vraisemblable
en raison de la relative stabilité des structures grammaticales d’un langage. La méthode
proposée est donc la suivante : Lorsqu’une hypothèse de reconnaissance de première passe est
associée à une mesure de consistance du modèle de langage CONS(LM) inférieure à 1, nous
vérifions la valeur de CONSPOS(LM) et identifions les Tri-grammes qui impliquent que
CONSPOS(LM) < 1, qui sont alors considérés comme peu plausibles. Dès lors, une phase de
rescoring est effectuée avec un modèle adapté où ces Tri-grammes sont fortement pénalisés. La
nouvelle hypothèse est soumise à la même procédure, et sera validée si CONS(LM) = 1, sinon
il est possible d’itérer la procédure. Cette stratégie permet de baisser le WER de 38% à
32% sur un ensemble de 45 phrases concernées du corpus de test de l’application AGS. Il
est intéressant de noter que certaines phrases sont totalement corrigées après l’opération
(WER=0%).
Les mesures de confiance linguistiques précédentes ont de bonnes capacités pour diagnostiquer la qualité
d’une phrase en terme de mots reconnus. L’utilisation conjuguée des différentes situations de
confiance déduites de ces mesures peut amener à la construction d’une stratégie plus complexe
de validation/rejet. Une stratégie élaborée faisant intervenir les notions précédentes a été
développée au début de cette thèse [Estève et al., 2003], elle n’est pas présentée dans ce
document.
Cette mesure de confiance fait la comparaison de la probabilité donnée par le modèle de reconnaissance de la parole pour une hypothèse donnée à celle qui aurait été obtenue par un modèle sans contrainte sur les boucles de phonèmes. Dans le but de rester consistant avec le modèle général, les unités acoustiques sont gardées identiques et la boucle est sur les phonèmes contexte dépendant, à savoir les allophones [Bartkova et Jouvet, 1991].
Pour une hypothèse W identifiée par le modèle général (λG) de la trame t0 à la trame tn, la probabilité du signal de parole Y est comparée à la probabilité de la même portion de signal sur une boucle non-contrainte d’allophones. La probabilité est définie comme suit :
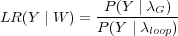 | (6.9) |
Dans le but de pouvoir comparer les mesures pour des mots différents, nous comparons actuellement les log-prob et nous normalisons la différence par le nombre de trames sur lesquelles elles sont calculées.
![Δloop(Y | W ) = logLR-(Y-| W-)=-----1----[log P(Y | λG)− logP (Y | λloop)]
Nframe(W ) Nframe(W )](these_v1.0122x.png) | (6.10) |
En pratique, Δloop(Y ∣W) est calculé à partir des scores acoustiques bruts produits par le processus de reconnaissance et :
![----1-----
Δloop(Y | W ) = Nframe(W )[ScG(Y )− Scloop(Y )]](these_v1.0123x.png) | (6.11) |
Du fait du relâchement des contraintes, la probabilité du signal de parole sur λloop est supérieure à celle sur λG. Cela peut être vu comme une borne supérieure pour P(Y ∣λG). Ainsi, Δloop(Y |W) est négatif et doit être interprété comme suit : au plus proche de zéro est la valeur, plus fiable est l’hypothèse W pour Y.
Dans le but, de donner un score aux différents concepts d’une hypothèse, la mesure précédente peut être facilement étendue au niveau conceptuel. En fait, le Δloop pour une séquence de mots est dérivé du Δloop de chaque mot la composant. Soit Γ une structure conceptuelle composée de n mots W1,...Wn, Δloop(Y ∣Γ) est approximée par :
 | (6.12) |
Cette mesure n’est pas évaluée ici, mais des résultats seront présentés dans le chapitre 7.
Lors de notre processus de décodage, un concept est détecté par notre modèle conceptuel lorsque une règle de grammaire reconnaît un certain patron. Nos grammaires tentent de récupérer la plus longue séquence de mots correspondant au concept détecté. Toutefois, en cas d’erreurs de reconnaissance, la grammaire peut ne pas détecter le concept si ces erreurs sont sur les mots-clefs, ou ne reconnaître qu’une séquence de mots limitée, si ces erreurs sont sur les mots autres que les mots-clefs. Dans le premier cas le concept n’est pas détecté par la grammaire (car dans ce cas il n’est pas possible d’en extraire une valeur), mais la présence d’autres types de mots peut infirmer ce résultat. Dans le second cas, si le concept est détecté avec une séquence de mots plus courte (et donc moins fiable car il peut s’agir d’un mot erroné isolé), la présence ou l’absence de certains mots contextuels peut également confirmer cette détection ou l’infirmer.
Comme nous le disions dans le chapitre 3.1, des méthodes à base de classifieurs peuvent être utilisées pour détecter des concepts dans une phrase. Nous proposons ici d’entraîner des classifieurs automatiques pour détecter la présence des concepts de l’application dans une intervention utilisateur. La détection conceptuelle faite par nos grammaires peut alors être confirmée ou infirmée en fonction de la décision du classifieur.
Les outils de classification de texte peuvent se différencier par la méthode de classification utilisée et par les éléments choisis afin de représenter l’information textuelle (mot, étiquette de Part Of Speech, lemme, stemme, sac de mots, sac de n-grams, longueur de phrase, etc.). L’objectif est d’entraîner des classifieurs à détecter les occurrences de chaque concept dans les interventions. À chaque concept détecté par nos grammaires, le classifieur ainsi entraîné peut donner son avis sur la présence de ce concept dans l’intervention. L’avis du classifieur sur la présence du concept devient une mesure de confiance pour ce concept.
Le corpus utilisé pour entraîner les classifieurs, est composé d’interventions utilisateur sous leur forme transcrite. Chaque transcription est étiquetée par son interprétation conceptuelle représentée par une séquence de constituants conceptuels basiques (ou concepts).
Dans les expériences menées sont utilisées les transcriptions manuelles du corpus d’apprentissage et les transcriptions manuelles et automatique du corpus de développement de l’application PlanResto. Chaque intervention est représentée sur plusieurs niveaux. Trois niveaux ont été utilisés :
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
À chaque intervention est alors associé l’ensemble des concepts présents, un exemple est disponible dans le tableau 6.5. À chaque exemple du corpus, et pour chaque concept de l’application, est noté la présence ou l’absence de ce concept. Un classifieur par concept est alors entraîné pour apprendre automatiquement des règles afin de pouvoir décider de la présence ou non d’un concept dans une phrase. Les scores donnés par le classifieur sont utilisés comme score de confiance.
Trois classifieurs sont utilisés dans les expériences suivantes : un basé sur les arbres de décisions LIA-SCT et deux autres sont des classifieurs à large-marge : BoosTexter et SVM-Torch.
LIA-SCT [Béchet et al., 2000] est un logiciel libre développé par le Laboratoire Informatique d’Avignon et disponible à l’adresse suivante : http://www.lia.univ-avignon.fr/chercheurs/bechet/. L’avantage principal de ce classifieur est de prendre en entrée une séquence de composants (qui peuvent être des descriptions de différents niveaux d’abstraction, comme des mots et des étiquettes morpho-syntaxiques, par exemple) afin de construire automatiquement, à chaque nœud de l’arbre, une expression régulière incluant ces composants qui peuvent s’appliquer à la globalité du tour de parole. À chaque feuille, les hypothèses conceptuelles sont associées à une probabilité.
BoosTexter [Schapire et Singer, 2000] est un classifieur basé sur une méthode de boosting de classifieurs à faible performance. Le but de cette méthode de classification à large-marge est de trouver une fonction qui maximise la marge entre les différents exemples à classer. Les classifieurs à faible performance sont passés en entrée. Ils peuvent être l’absence ou la présence d’un mot ou d’un n-gram spécifique, une valeur numérique (comme la longueur de la phrase prononcée) ou une combinaison de cela. À la fin du processus d’entraînement, la liste des classifieurs sélectionnés est obtenue ainsi que les poids de chacun d’entre eux dans le calcul du score final pour chaque constituant de la liste des concepts. Les éléments choisis dans nos expériences sont des 1-gram, 2-gram et 3-gram sur les trois niveaux présentés dans la section 6.5.2.
SVM-Torch [Collobert et al., 2002] est un classifieur basé sur les SVMs dont l’entrée est un vecteur d’éléments numériques. Dans nos expériences, la technique la plus simple du sac de mots est utilisée : un tour de parole est représenté comme un vecteur dont chaque composante correspond à un élément appartenant à un des trois niveaux présenté dans la section 6.5.2 et chaque composante a pour valeur le nombre d’occurrence de l’élément correspondant dans le tour de parole.
|
Dans l’exemple du tableau 6.6, on peut voir que le système de reconnaissance propose comme candidat, une hypothèse X où le mot-clef est erroné. La grammaire détecte alors un LIEU, à la place d’un PRIX. Pourtant il paraît évident que dans ce contexte c’est un PRIX qui a été prononcé. En s’appuyant sur ce contexte l’arbre de classification nous donne une probabilité très faible que le concept LIEU soit présent dans l’hypothèse X (0.17) et très forte que le concept PRIX y soit (0.90), la mesure de confiance nous permet d’infirmer ici, la détection faite par la grammaire sur l’hypothèse X et confirme au contraire celle sur l’hypothèse Y.
Nous avons présenté dans ce chapitre des travaux sur un panel de mesures de confiance. Ces mesures de confiance permettent de diagnostiquer la sortie de reconnaissance à différents niveaux (mot, phrase, concept) et avec différents critères (linguistique, acoustique, sémantique). Au niveau de la phrase, deux mesures de confiance linguistiques ont été présentées. Elles sont fondées autour de l’idée que l’utilisation de méthodes de repli peut être source d’erreurs de reconnaissance. La première exploite des situations consensuelles obtenues par des décodages en parallèle effectués avec des modèles de langage « augmentés » créés pour pallier le manque de données d’apprentissage. La seconde mesure l’impact négatif d’utilisation de ces méthodes en identifiant la proportion d’événements dans la phrase reconnue ayant une probabilité calculée par une méthode de repli. Une mesure de confiance acoustique intervenant au niveau des mots a été présentée et étendue au niveau conceptuel (i.e. à la séquence de mots relative à un concept). Nous avons présenté une mesure de confiance fonctionnant au niveau conceptuel qui utilise des méthodes de classification automatiques pour détecter des concepts dans une transcription afin de valider les détections faites par les grammaires. Ce chapitre a mis en évidence un ensemble d’outils pour diagnostiquer des hypothèses de sortie du module RAP. Nous nous proposons dans le chapitre suivant de mettre en place une stratégie d’aide à la décision pour le gestionnaire de dialogue en utilisant ces mesures de confiance sur notre liste structurée.