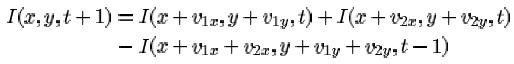Vincent Auvray - Contributions
(Retour)
Bref apercu de la problèmatique de l'estimation de mouvements transparents
Trois grands types de méthodes sont proposées dans la littérature pour estimer les mouvements transparents:
L'adaptation partielle d'estimateurs de mouvements classiques (Black et Anandan, Irani et Peleg), mais seulement pour des transparences
partielles.
La détection de plans dans l'espace de Fourier 3D (Shizawa et Mase, Pingault et Pellerin, Stuke et Aach), mais elle nécessite
des mouvements translationnels sur quelques dizaines de frames.
L'estimation de mouvements transparents dans l'espace direct (Pingault et Pellerin, Stuke et Aach, Toro), qui s'appuie sur une
équation équivalente à la conservation de l'intensité:
Elle suppose les mouvements constants sur deux intervalles de temps consécutifs.
C'est dans cette troisème voie que nous nous inscrivons. (Plus)
Nos travaux en situation de bitransparence
Nous avons dans un premier temps imaginé un mécanisme de formation d'images
synthétiques respectant la physique de formation des images par rayons X, afin de pouvoir construire des séquences de test
à vérité de terrain connue, sur lesquels évaluer nos estimateurs. (Plus)
Nous avons développé trois générations d'estimateurs de mouvement transparents adaptés au cas ou
l'image est composée de deux couches transparentes (Et deux couches seulement!).
Nos premiers travaux (présenté à GRETSI'05 et à
ICIP'05) ne permettaient pas encore d'atteindre de précision intéressante sur
des séquences cliniques réalistiquement bruitées.
C'est pourquoi nous avons imaginé un deuxième algorithme, présenté à MICCAI'05.
Pour etre autant robustes au bruit que possible tout en gardant des temps de calculs raisonnables, nous avons cherché à
contraindre au maximum le problème. Des observations de nombreuses séquences réelles nous ont convaincu que
les mouvements anatomiques (battements du coeur, dilatation des poumons, translation du diaphragme) pouvaient etre modelisés par
des champs de déplacements affines.
Ces travaux permettent d'atteindre une précision
d'estimation de 0.75 et 2.85 pixels sur des images typiques d'examens diagnostiques et interventionnels respectivement.
Nous avons alors proposé à ICIP'06 une évolution de cet algorithme, qui mene à
des précisions de 0.6 pixels sur images diagnostiques et 1.2 sur images fluoroscopiques, ainsi que des exemples réels.
(Plus) (Demos)
 Champs de mouvements estimés sur une portion d'examen cardiaque en situation de bi transparence.
Champs de mouvements estimés sur une portion d'examen cardiaque en situation de bi transparence.
Nos travaux en situation de bitransparence distribuée
Nos contributions jusque là (comme la plupart des travaux sur le sujet)
estiment les mouvements transparents dans une séquence d'images ne présentant qu'une configuration
unique: deux couches animées d'un mouvement cohérent étaient présentes partout sur l'image.
Or, les images réelles sont plus complexes: elles contiennent plus de deux couches en tout, mais rarement plus de deux au
meme point. C'est ainsi que nous avons introduit le concept de bitransparence distribuée pour désigner des
images pouvant etre segmentees en zones contenant au plus deux couches.
Nous présentons à ICIP'06 une méthode d'estimation et de segmentation
jointe de mouvements transparents, menant lui aussi à des précisions de 0.6 pixels sur images diagnostiques et 1.2 sur
images fluoroscopiques. (Plus)
 Deux images d'une séquence de fluoro, les champs calculés (le champ correspondant au fond est invisible
car il est nul), et la segmentation obtenue.
Deux images d'une séquence de fluoro, les champs calculés (le champ correspondant au fond est invisible
car il est nul), et la segmentation obtenue.
 Traitement d'une séquence vidéo de bi-transparence distribuée. En haut à gauche la
segmentation des couches, en haut à droite les champs de vecteur estimés, et en bas les images de différence
recalées.
Traitement d'une séquence vidéo de bi-transparence distribuée. En haut à gauche la
segmentation des couches, en haut à droite les champs de vecteur estimés, et en bas les images de différence
recalées.
Nous proposons également une démo détaillant le fonctionnement de
l'estimateur.
L'application au débruitage
Il nous faut aussi savoir comment utiliser cette information du mouvement pour débruiter nos séquences. En vidéo
classique, il suffit de moyenner la valeur d'un pixel selon sa trajectoire pour mettre au point un filtre des plus efficaces.
Il est par contre impossible dans notre cas d'appliquer la meme méthode car nous ne pouvons pas suivre les points physiques du fait
de la transparence: meme en connaissant parfaitement les mouvements d'un point du poumon, nous ne pouvons pas remonter à son
niveau de gris car des objets toujours différents s'y ajoutent. La seule facon de faire serait de séparer les couches mais ce travail est très délicat, meme
si quelques auteurs proposent des méthodes intéressantes pour le faire (Sarel et Irani,
Separating Transparent Layers through Layer Information Exchange).
Nous avons préféré proposer une approche ne nécessitant pas cette séparation dans
MICCAI'05. L'équation de conservation de l'intensité appliquée
à la transparence peut en effet etre lue comme suit:
En d'autres termes, il est possible de prédire l'image à la date t+1 à partir des deux images
précédentes décalées. D'où l'idée d'appliquer le filtrage temporel entre cette image
prédite et l'image mesurée à t+1: elles représentent la meme réalité physique
et ne différent que par les réalisations du bruit. Nous sommes donc en position idéale pour filtrer temporellement
la séquence compensée et donc réduire le bruit sans introduire aucun artefact.
Seulement, l'étape de prédiction suppose l'addition de trois images et a donc un coût en terme d'augmentation
du bruit. Et en effet, meme en réglant les poids du filtre temporel de manière optimale on ne peut jamais dépasser
la limite asymptotique de 20% de débruitage, ce qui est très décevant.(Retour)
Nous avons alors développé un nouveau type de filtres, dit hybrides, qui arbitrent localement entre différents
types de compensation:
Compensation de mouvements transparents lorsque les deux couches considérées sont texturées.
Compensation de la couche la plus texturée dans tous les autres cas (seule une couche est texturée, ou les deux couches sont homogènes).
On conserve alors toute l'information utile sans limiter le débruitage.
Ce type d'approche est utilisable à la fois pour le filtrage de bruit purement temporel, et le filtrage spatio-temporel. Dans le premier
cas, nous obtenons un débruitage de l'ordre de 50% en écart-type, sans filtrage de l'information utile. (soumission à ISBI'07 en cours).
 Traitement d'une séquence fluoroscopique traitée avec le filtre hybride temporel (à gauche),
et avec un filtre temporel adaptatif (à droite). Le coeur est nettement mieux contrasté à gauche qu'à
droite, pour un débruitage équivalent.
Traitement d'une séquence fluoroscopique traitée avec le filtre hybride temporel (à gauche),
et avec un filtre temporel adaptatif (à droite). Le coeur est nettement mieux contrasté à gauche qu'à
droite, pour un débruitage équivalent.
Retour