



Next: Unités entières et
Up: Séquencement et exécution
Previous: Introduction
La tendance actuelle est à l'accroissement du nombre d'étages de pipelines pour l'exécution des instructions, ceci pour deux raisons principales :
- Le fait de découper plus finement le pipeline simplifie les étages de pipeline. Ceci permet de réduire le temps de cycle du microprocesseur.
- La gestion des dépendances entre les instructions est de plus en plus complexe avec l'exécution des instructions en parallèle et dans le désordre.
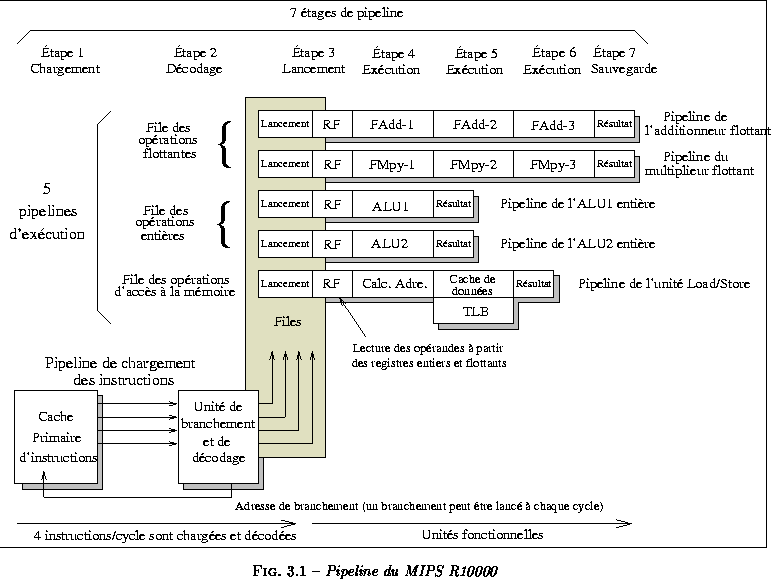
Le microprocesseur superscalaire MIPS R10000 peut charger et décoder quatre instructions en parallèle par cycle d'horloge. Il est composé de cinq unités fonctionnelles indépendantes (voir figure  ). L'interaction entre ces pipelines est gérée par les trois files d'attente (file des instructions entière, file des instructions flottantes et file des instructions mémoire). Les cinq unités d'exécution ont des pipelines d'exécution indépendants. Elles partagent en amont le pipeline de chargement des instructions. Ce pipeline lit les instructions à partir du cache d'instructions, les décode, renomme les registres afin de résoudre les fausses dépendances inter-registres et place les instructions dans les files d'attente appropriées. À partir de ces files, les instructions sont dynamiquement émises dans les cinq pipelines d'exécution.
). L'interaction entre ces pipelines est gérée par les trois files d'attente (file des instructions entière, file des instructions flottantes et file des instructions mémoire). Les cinq unités d'exécution ont des pipelines d'exécution indépendants. Elles partagent en amont le pipeline de chargement des instructions. Ce pipeline lit les instructions à partir du cache d'instructions, les décode, renomme les registres afin de résoudre les fausses dépendances inter-registres et place les instructions dans les files d'attente appropriées. À partir de ces files, les instructions sont dynamiquement émises dans les cinq pipelines d'exécution.
- À la première étape (étage de chargement du pipeline), le MIPS R10000 charge quatre instructions à partir du cache d'instructions, indépendamment de leur alignement. Les instructions ne peuvent être prises à travers des blocs de plus de 16 mots. Ces instructions sont ensuite alignées dans des registres d'instructions de quatre mots.
- Étape 2 (étage de décodage du pipeline) : les quatre instructions chargées sont décodées et les registres opérandes et résultats sont renommés (voir paragraphe ). Ces instructions renommées sont ensuite émises vers les files d'attente des unités fonctionnelles correspondantes.
- Étape 3 : les instructions décodées sont placées dans les files d'attente. Le troisième étage peut aussi être le début des pipelines d'exécution. En cas de disponibilité des registres opérandes d'une instruction de branchement, la prédiction de branchement est vérifiée à cet étage sur l'ALU1. Les instructions exécutables sont retirées des files d'attente et les registres opérandes sont lus. La durée du passage d'une instruction dans cet étage du pipeline est très variable et dépend de la disponibilité de ses opérandes.
- Étapes 4 à 6 : au cours de ces étapes, les instructions sont exécutées dans les différentes unités d'exécution :
- Additionneur flottant, multiplieur flottant et unité de division flottante et de racine carrée. Le fonctionnement des unités flottantes est décrit au chapitre .
- ALU1. Les opérations d'addition, de soustraction, de décalage et les opérations logiques sont exécutées avec un cycle de latence.
- ALU2. Les opérations d'addition, de soustraction et les opérations logiques sont exécutées avec un cycle de latence. Les opérations de multiplication et de division sont plus longues.
- L'unité load/store calcule l'adresse à l'étape 4 puis accède au TLB et au cache de données à l'étage 5. Le résultat est écrit dans le fichier de registres au cycle 6.
- Calcul de traduction d'adresse dans le TLB. Une seule adresse mémoire peut être calculée à chaque cycle.
- Étape 7 : Sauvegarde des résultats des unités flottantes.

Le microprocesseur UltraSPARC peut charger et décoder quatre instructions, alignées en mémoire, en parallèle par cycle d'horloge. Il utilise neuf étages de pipeline (figure ). Le pipeline entier utilise en fait six étages, mais l'étage d'écriture des résultats est retardé de trois cycles afin de permettre une gestion précise des exceptions. Les étages supplémentaires à la fin du pipeline sont utilisés par les unités flottantes et graphiques. Selon les concepteurs de l'UltraSPARC, cette approche évite l'implémentation d'une file pour les instructions flottantes (au contraire des implémentations SPARC V7 ou SPARC V8).
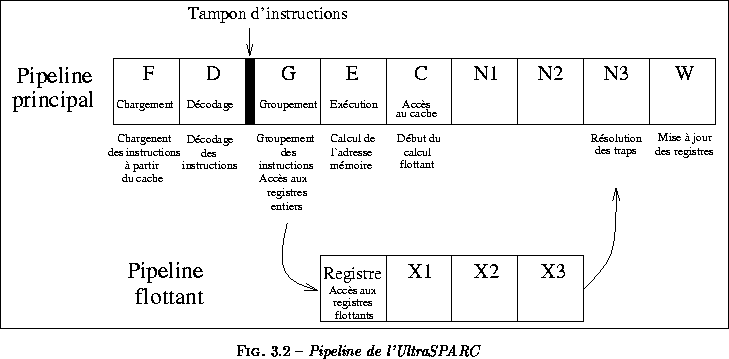
- Étage de chargement : les instructions chargées à partir du cache d'instructions sont placées dans un tampon d'instructions où elles vont être éventuellement sélectionnées pour être exécutées. Jusqu'à quatre instructions peuvent être lues dans le cache d'instructions simultanément. Les instructions doivent être alignées en mémoire.
- Étage de décodage : les instructions sont décodées puis envoyées dans le tampon d'instructions de 12 entrées. Les bits de décodage sont envoyés dans le tampon d'instructions avec l'instruction. Ce tampon permet de découpler le chargement des instructions de leur exécution. En même temps, le tampon d'instructions présente quatre instructions à l'étage de pipeline suivant.
- Étage de groupement : cet étage de pipeline lit quatre instructions valides dans le tampon d'instructions et lance dans l'ordre les instructions exécutables, c'est-à-dire, les instructions dont les opérandes sont disponibles et pour lesquelles une unité fonctionnelle est disponible. Les registres entiers sont lus à cet étage.
- Étage d'exécution : l'exécution des instructions entières a lieu à cet étage. Pour les instructions load/store, l'adresse virtuelle des accès mémoire est calculée. Le fichier de registres flottants est lu à cet étage.
- Étage d'accès au cache : l'adresse virtuelle des load/store est présentée au cache de données. L'adresse physique est obtenue à la fin de l'étage dans lequel le TLB est accédé. Les codes conditions générés par les opérations des ALUs au cycle précédent sont utilisés pour vérifier si les branchements conditionnels ont été prédits correctement ou non.
- Étages X1, X2 et X3 du pipeline flottant et graphique : étages d'exécution du pipeline flottant.
- Étage N1 : les défauts sur le cache de données sont détectés à cet étage (l'adresse physique est utilisée pour la vérification des étiquettes) et envoyés vers un tampon de lecture de neuf entrées. L'adresse physique d'un store est envoyée au tampon d'écritures.
- Étage N2 : la plupart des instructions flottantes finissent leur exécution à cet étage. Après cet étage, les données peuvent être directement utilisées (à travers un mécanisme de chaînage), ou retournées vers le champ de données du tampon d'écritures.
- Étage N3 : l'UltraSPARC utilise cet étage spécifique pour résoudre les exceptions.
- Étage W : tous les résultats sont écrits dans les fichiers de registres (entiers ou flottants). Les exceptions ayant été résolus à l'étage précédent, seules les instructions ne générant pas d'exceptions atteignent cet étage.
Les deux pipelines d'exécution entiers ne sont pas identiques. Les opérations de décalage ainsi que celles ayant trait aux codes conditions ne peuvent être exécutées que dans un pipeline. On notera aussi que le fichier de registres flottants est accédé un cycle après le fichier de registres entiers. Ce décalage est un compromis. En effet, pour pouvoir lancer une opération flottante, on a souvent besoin d'une donnée lue en mémoire. En retardant artificiellement l'opération flottante, on permet au réordonnanceur d'instructions de mieux grouper les instructions parallélisables.
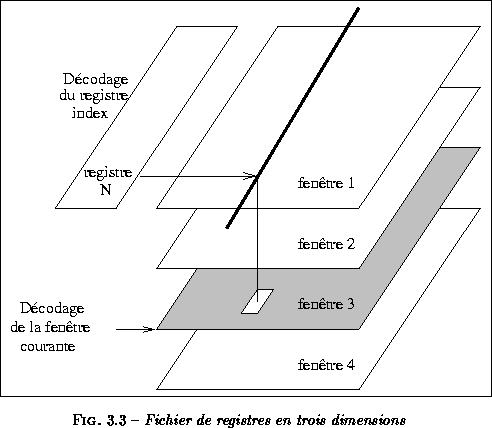
L'UltraSPARC exécute les instructions dans l'ordre, le renommage des registres est donc inutile. Par contre, le jeu d'instructions SPARC utilise des fenêtres de 16 registres. Plusieurs fenêtres de registres sont implémentées : l'UltraSPARC intègre 8 fenêtres de registres, soit 128 registres, plus 4 jeux de 8 registres globaux. Un tel fichier de 160 registres est énorme, surtout quand 10 ports d'accès sont nécessaires. En fait, toutes les fenêtres de registres ne sont pas accédées simultanément ; ce qui permet de partager les chemins de données des fenêtres. Ceci est réalisé dans l'UltraSPARC par l'implémentation d'un fichier de registres en trois dimensions[14]. Ceci est représenté figure . Chaque plan représente une fenêtre de registres. Le pointeur de fenêtre est décodé et le plan correspondant est selectionné. Une seule fenêtre de registres est accédée à chaque cycle. Mais les chemins de données sont communs à toutes les fenêtres.
Le PentiumPro utilise un pipeline de 12 étages beaucoup plus long que ceux du MIPS R10000 et de l'UltraSPARC. Cette profondeur de pipeline, qui lui permet d'atteindre une fréquence d'horloge élevée, est due à la traduction des instructions en micro-opérations (trois cycles et demi) et à la présence d'un cycle de prédiction de branchement dans la présentation du pipeline. Ce cycle, présent sur tous les microprocesseurs, est ignoré dans les autres présentations de microprocesseurs. La figure présente ce pipeline .
.
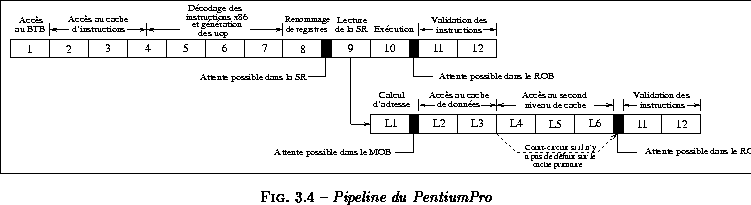
- Au premier étage du pipeline, l'adresse du bloc d'instructions suivant est calculée grâce au Branch Target Buffer (BTB). Si un branchement est prédit <<pris>>, le flot d'instructions est redirigé vers la nouvelle adresse renvoyée par le BTB. Dans le cas contraire, le bloc suivant d'instructions est chargé.
- L'accès au cache d'instructions nécessite deux cycles et demi. En découpant l'accès au cache en plusieurs étapes, Intel réduit les chemins critiques et permet ainsi au PentiumPro d'atteindre une fréquence d'horloge élevée.
- Les instructions sont ensuite envoyées aux décodeurs d'instructions qui vont les convertir en micro-opérations. Il faut trois cycles et demi au PentiumPro pour réaliser cette opération.
- À la fin du septième étage de pipeline, les instructions sont entièrement décodées et traduites en micro-opérations.
- Au huitième étage de pipeline, les registres sont renommés et les micro-opérations sont placées dans la station de réservation.
- Toute micro-opération doit passer au moins un cycle dans la station de réservation. Le PentiumPro implémente un mécanisme de chaînage qui permet au résultat d'une opération d'être utilisable au cycle suivant. Les micro-opérations attendent toujours leurs opérandes dans la station de réservation.
- Les micro-opérations entières simples (opérations sur l'ALU) peuvent être exécutées en un seul cycle (étage 10). Les autres micro-opérations entières ainsi que toutes les micro-opérations flottantes sont exécutées en plusieurs cycles. Les micro-opérations de type load et store génèrent leur adresse en un cycle et sont écrites dans le Memory Reorder Buffer (MOB). Si le MOB est vide, un load sera directement envoyé au cache de données, mais il faudra un cycle supplémentaire avant que la donnée ne soit utilisable.
- Les micro-opérations exécutées sont signalées au ReOrder Buffer (ROB). Le Reorder Buffer valide les instructions dans l'ordre du programme ; la validation d'une micro-opération donnée peut attendre plusieurs cycles dans le ROB.
Dans le pipeline illustré figure , les instructions peuvent être bloquées à trois étapes différentes :
- une instruction peut être bloquée dans la station de réservation pendant quelques cycles, en attente de la disponibilité de ses opérandes ;
- une instruction attendant la fin de son exécution peut être bloquée dans le ROB avant d'être retirée ;
- une instruction load ou store peut être bloquée dans le Memory Reorder Buffer.
Il ne faut cependant pas croire que ce sont les seuls endroits où le séquencement d'une instruction est retardée. L'instruction peut aussi être retardée par l'étape de génération des micro-opérations, à l'entrée de la station de réservation et bien entendu pour des défauts de cache. Tout laisse à penser que le temps moyen entre l'initialisation d'une instruction à l'étage 1 et son achèvement à l'étage 12 est bien supérieur à 12 cycles.
Next: Unités entières et
Up: Séquencement et exécution
Previous: Introduction