



Next: Technologie
Up: Architecture : vue
Previous: Introduction
La vue générale du MIPS R10000 est présentée à la figure  . Le MIPS R10000 intègre, au sein d'un même composant, cinq unités fonctionnelles principales, ainsi que deux caches primaires séparés (32 Koctets pour les données et 32 Koctets pour les instructions). Les cinq unités fonctionnelles principales sont :
. Le MIPS R10000 intègre, au sein d'un même composant, cinq unités fonctionnelles principales, ainsi que deux caches primaires séparés (32 Koctets pour les données et 32 Koctets pour les instructions). Les cinq unités fonctionnelles principales sont :
- deux unités arithmétiques et logiques entières (ALU1 et ALU2) ;
- une unité de calcul d'adresses pour les loads et les stores ;
- une unité d'addition flottante ;
- une unité de multiplication flottante.
Trois sous-unités fonctionnelles itératives sont utilisées pour le calcul d'opérations plus complexes :
- une unité de multiplication et division entière intégrée dans l'ALU2 ;
- une unité de division flottante et une unité de calcul de racine carrée, intégrées dans l'unité de multiplication flottante.


L'exécution des instructions peut être exécutée dans le désordre. Les unités fonctionnelles sont alimentées par trois files d'attente d'instructions appelées <<stations de réservations>> : soit, une file pour les instructions mémoires (Memory Queue), une file pour les instructions entières (Integer Queue) et une file pour les instructions flottantes (FP Queue). À partir d'une file d'attente, une instruction exécutable peut être envoyée dans une unité d'exécution avant une instruction antérieure qui attend une ou plusieurs de ses opérandes. Ces trois files sont alimentées par l'unité de chargement et de décodage qui gère de plus les dépendances entre les instructions à travers l'Active list.
peut être envoyée dans une unité d'exécution avant une instruction antérieure qui attend une ou plusieurs de ses opérandes. Ces trois files sont alimentées par l'unité de chargement et de décodage qui gère de plus les dépendances entre les instructions à travers l'Active list.
- Les unités entières du MIPS R10000 appelées ALU1 et ALU2 traitent les opérations entières d'addition, de soustraction et les opérations arithmétiques et logiques. L'ALU1 traite les opérations de branchement et de décalage et l'ALU2 les opérations de multiplication et d'addition.
- L'unité de calcul d'adresses comprend un additionneur, une file d'adresses et un TLB.
- L'unité flottante du MIPS R10000 est composée de deux sous-unités flottantes : l'une pour les opérations d'addition et de soustraction, et l'autre pour les opérations de multiplication et de division.
Le MIPS R10000 comprend d'autre part un cache d'instructions de 32 Koctets, un cache de données de 32 Koctets ainsi qu'un contrôleur de cache pour le cache secondaire externe.
La vue générale de l'UltraSPARC est illustrée à la figure . L'UltraSPARC intègre au sein d'un seul composant les unités fonctionnelles suivantes :
- une unité de préchargement des instructions, de prédiction de branchements et d'émission des instructions (Prefetch and Dispatch Unit (PDU)) ;
- une unité de gestion mémoire de 64 entrées pour les instructions et de 64 entrées pour les données (Memory Management Unit (MMU)) ;
- une unité d'exécution entière composée de deux ALUs (Integer Execution Unit (IEU)) ;
- une unité load/store (Load/Store Unit (LSU)) ;
- un tampon pour les loads et un tampon pour les stores ;
- un cache de données de 16 Koctets ;
- un cache d'instructions de 16 Koctets ;
- une unité flottante composée de trois sous-unités indépendantes (addition, multiplication et division/racine carrée) (Floating-Point Unit (FPU)) ;
- une unité graphique composée de deux pipelines d'exécution séparés (Graphics Unit (GRU)) ;
- une unité responsable de la mémoire principale et des entrées/sorties (Memory Interface Unit (MIU)).
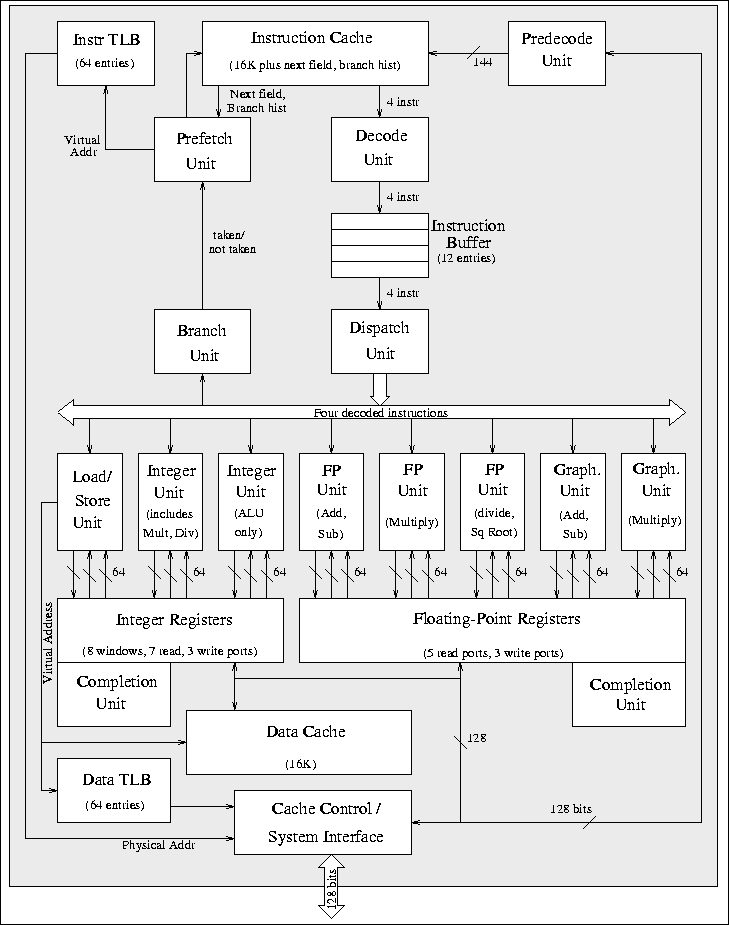
- L'unité de préchargement et de lancement (PDU) charge des instructions en avance sur l'exécution du programme. Jusqu'à quatre instructions peuvent être lues par cycle. Pour pouvoir précharger des instructions de branchements conditionnels, l'UltraSPARC implémente une technique de prédiction de branchement dynamique. Les instructions préchargées sont rangées dans le tampon d'instructions en attendant d'être émises vers le reste du pipeline. Le tampon d'instructions peut contenir 12 entrées. À noter que jusqu'à quatre instructions par cycle peuvent être émises dans l'ordre aux unités fonctionnelles.
- L'unité de gestion de la mémoire (MMU) est chargée de la traduction des adresses virtuelles (calculées sur 44 bits) en adresses physiques sur 41 bits. Le cache de traduction (TLB) possède 64 entrées pour les instructions et 64 entrées pour les données. Ces deux TLBs sont totalement associatifs.
- La partie principale de l'unité d'exécution entière (IEU) est composée de deux ALUs entièrement pipelinées. Elle intègre aussi un multiplieur et diviseur entier multi-cycle. L'unité implémente en outre huit fenêtres de registres et quatre ensembles de registres globaux.
- L'unité Load/Store (LSU) génère les adresses virtuelles pour tous les loads et tous les stores et est responsable des accès au cache de données.
- L'unité flottante (FPU) possède des unités d'exécution séparées. Celles-ci permettent à l'UltraSPARC d'exécuter deux instructions flottantes par cycle d'horloge. La FPU travaille sur un fichier de 32 registres de 64 bits. La plupart des instructions sont complètement pipelinées. Seules les instructions de division et de racine carrée ne sont pas pipelinées. Par contre, ces instructions ne bloquent pas les autres unités fonctionnelles.
- L'unité graphique (GRU) traite les instructions permettant le calcul d'images en deux et trois dimensions, la compression d'images, le traitement vidéo... Cette unité, intégrée à l'unité flottante, est composée, entre autre, d'un additionneur et d'un multiplieur. Toutes les opérandes pour la GRU sont chargées à partir du fichier de registres de l'unité flottante.
- Toutes les transactions avec le contrôleur de système, comme les défauts de caches, les interruptions... sont traitées par la l'unité d'interface mémoire (MIU).
Le PentiumPro est un microprocesseur superscalaire comme son prédécesseur le Pentium [12][3]. Le PentiumPro intègre dans un même boîtier (MCM) le microprocesseur et un cache secondaire sur un second composant. Deux versions sont annoncées : l'une avec un cache secondaire de 256 Koctets, et l'autre avec un cache secondaire de 512 Koctets (cette version devrait être disponible au cours du premier trimestre 1996).
L'architecture interne du microprocesseur est radicalement différente des architectures de ses prédécesseurs (80486 et Pentium). La différence essentielle est que le PentiumPro traduit ses instructions en micro-opérations au cours des premiers étages du pipeline.
Le PentiumPro décompose les instructions x86 en micro-opérations de taille constante. Cette approche est déjà utilisée par le K5 d'AMD et le 586 de NexGen. Ces micro-opérations de 118 bits de long sont alors exécutées dans le coeur superscalaire capable de renommer les registres et d'exécuter ces micro-opérations dans le désordre. Elles ont une structure régulière pour encoder l'opération, les deux opérandes source et la destination. Comme les instructions RISC, les micro-opérations utilisent un modèle de type load/store. Une instruction x86 qui accède un de ses opérandes en mémoire sera traduite en une micro-opération load, une micro-opération ALU et éventuellement en une micro-opération store. D'après Intel, la plupart des instructions génèrent en moyenne 1,5 à 2 micro-opérations.
On peut diviser l'architecture du PentiumPro en trois grandes parties : une partie décodant les instructions dans l'ordre du programme (Fetch and Decode Unit), une partie où les instructions sont exécutées dans le désordre (Dispatch and Execute Unit), et enfin, une partie où les instructions sont validées dans l'ordre logique du programme par une unité de remise en ordre appelée Retire Unit.
- L'unité de chargement et de décodage (Fetch and Decode Unit) produit les instructions dans l'ordre du programme.
- L'unité de lancement et d'exécution (Dispatch and Execute Unit) consomme les instructions dans le désordre.
- L'unité de validation (Retire Unit) valide l'exécution des instructions dans l'ordre logique du programme.
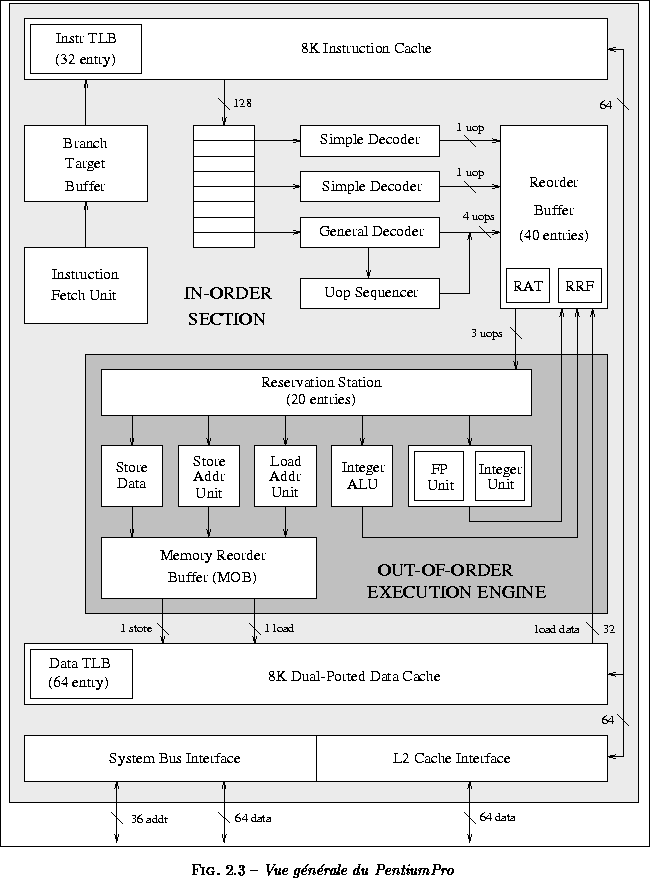
Nous allons maintenant présenter la composition des différentes unités fonctionnelles (voir figure ) :
- l'unité de chargement et de décodage prend en entrée le flot d'instructions venant du cache d'instructions. Elle décode les instructions et les traduit en micro-opérations. Cette unité est composée :
- d'une unité de chargement d'instructions et d'un cache d'instructions de 8 Koctets.
- d'un Branch Target Buffer de 512 entrées pour effectuer les prédictions de branchement ;
- de trois décodeurs qui transforment les instructions en micro-opérations ;
- d'un séquenceur de micro-opérations ;
- et d'un tampon de 40 entrées pour la remise en ordre des instructions (Reorder buffer).
- l'unité de lancement et d'exécution exécute les instructions venant de l'unité Fetch/Decode en fonction des dépendances de données et des conflits de ressources. Les résultats des instructions sont temporairement sauvegardés. Cette unité intègre les unités suivantes :
- une station de réservation de 20 entrées ;
- un tampon pour les loads et un tampon pour les stores ;
- une unité de calcul d'adresses ;
- une unité entière et flottante ;
- et une ALU entière.
- l'unité de validation achève l'exécution des instructions en les retirant du Reorder Buffer et en sauvegardant les résultats dans l'ordre de séquencement du programme.
Next: Technologie
Up: Architecture : vue
Previous: Introduction